MDX statements
- Jan. 13, 2026
Introduction
MDX statements are what SQL queries are to relational databases, but instead acting on OLAP (multidimensional) databases. In the case of TM1, we will use these expressions to query a dimension (hierarchy) and its members, cubes and their data points, etc. You will find out that a lot is possible if you get the syntax right.
Topics
Sources
Credits
use-cases
Referencing elements
Using an existing subset in an expression
Elements at different levels
Sorting
Descendants and Ascendants
More on hierarchical structures
Planning Analytics hierarchies
Union and Intersect
Cube values
Filtering on attributes
Double lookups
Filtering over dimensions
Filtering with wildcards
More on sorting
Generate
Subsets based on other objects
Distinct elements
Orphans and top consolidations
TM1 users and groups
Application and control objects
Temporary subsets
TM1ELLIST
IS
Count
Escape character
Caveats
Excel
MDX views
Sources
Writing MDX statements will not be that easy, certainly not in the beginning. Where can you find help ?
- This very page you are looking at ! In all honesty and humbleness, it contains very good material.
- This very nice overview with other practical examples by George Tonkin.
- This high-quality overview for more details, written by Phillip Bichard and Martin Findon.
- MDX for views written by George Tonkin (see all parts of the series).
- Microsoft documentation on the topic. Also, see member properties and several related pages.
- Functions in IBM DB2. Mind you, not all these functions are supported in Planning Analytics, however it may add some more information you may find useful.
- TM1 has a 'Record expression' functionality:
- PAW has equivalent functionality, where you could insert elements and make manipulations, then get the see/change/commit the generated MDX behind. Due to autocomplete of functions you can also see what is supported and learn from that.
- Working with Time Related MDX Functions by George Tonkin (you need an IBM ID to access).

Record the relevant steps, much like the Macro recorder in MS Office applications - Visual Basic for Applications or VBA for short.
Credits
I already dropped the name, George Tonkin. A great number of discoveries were done by him and he shared them to me and the TM1 community via this page but also through the TM1 forum. He does a lot of effort to advance the collective knowledge on things like MDX and REST API in the TM1 community. This page would not nearly be the same without his contributions. Send him a big thank you and please make sure to share your own findings with George and myself. Countless hours (or weeks) went into collecting and testing the information below and I (we) appreciate any comment / remark / addition / error correction.
MDX use-cases
As a TM1 developer, we mainly use MDX statements in the following cases:
- to make dynamic subsets rather than static subsets. For example, a cubeview showing the sales of the customers who bought last month as well (and only those customers);
- to create custom views in a Turbo Integrator (TI) process. We will often zero out (part of) a cube, this is clearing cells at the lowest level elements in certain dimensions. This list of elements can be generated with no need to loop through the dimension ourselves.
- Active forms in Excel have dynamic row subsets, you can expand and contract consolidations. The list of elements in the rows can again be an MDX statement, even quite complex statements.
Mind the syntax, it is crucial to get that straight. If not, TM1 won‘t like it… Some of the statements can be generated in the Subset Editor: turn on the Properties Window (menu View), then choose Tools > Record Expression. Record the expression while you do the steps manually. Stop recording when you are finished.
General tips
the following high-level tips should be taken into account:
- As MDX statements lead to dynamic selections of elements, it is important to keep performance in mind. Usually it's all really quick but pay attention to large dimensions with deeply nested consolidation structures. One would argue that at least elements that are not needed in the dimension, and do not contain historical data, should be removed from the dimension.
- Try to keep the definition of MDX subsets rather condensed instead of having MDX expressions with thousands of characters. For instance, if you re-use the same code within 1 or more dynamic subsets, consider adopting a more modular approach. Create a different (public) subset with that piece of logic and use the resulting subset in other MDX statements. Refer to TM1SubsetToSet below in the text. It will certainly lead to more maintainable subsets and MDX expressions.
- Turbo Integrator could be used to set up bunches of MDX-driven subsets, if you like. No need to create/update them all manually. TI could also easily convert dynamic subsets into static subsets.
Often used MDX statements
Below, I will present you the MDX statements I need most of the time. This page will therefore serve as a kind of code library: we can copy/paste and adjust only names of cubes/dimensions/elements. You will notice [] around dimension names and element names. They could be left out, unless (for instance) the name contains a space. Then we must enclose the name with []. The expressions are most of the time case-insensitive. Except for function names, the expressions are also space-insensitive.
Referencing elements
{[Project_type].[All types]}
or:
{[FIN_Year].[2025]}
SubsetCreatebyMDX('Subset_Years', '{[FIN_Year].[2025]}');
becomes:
SubsetCreatebyMDX('Subset_Years', '{[FIN_Year].['|pYear|']}');
The function EXPAND in TI can be used to substitute variable names to their values at run-time: SubsetCreatebyMDX('Subset_Years', EXPAND('{[FIN_Year].[%pYear%]}'));
{[FIN_Year].[2024], [FIN_Year].[2025]}
SubsetCreateByMDX( vSubset, 'Descendants( TM1FilterByPattern( TM1SubsetAll([ ' | Dim1 | ']), ' | vConso | ' ))' );
compared to:
SubsetCreateByMDX( vSubset, Expand( 'Descendants( TM1FilterByPattern( TM1SubsetAll([%Dim1%]), %vConso% ))' ));
="{[FIN_Year].[" & E15 & "],[FIN_Year].[" & E16 & "]}"
This allows you to customize your reports to a great extent. For example, the user can sort the rows ascending or descending, where these 2 options are a selection in a cell. The choice of the user is then picked up in the MDX expression at hand.
{[Account].Members.Item(5)}
This gives us the 6th account, index-wise, since we start counting at 0.
Using an existing subset in an expression
{TM1SubsetToSet([Period].[Period], "Current Period", "public")}
This expression uses the contents of the "Current period" subset within the Period hierarchy of the Period dimension.
The public/private character of the referenced subset was submitted by George Tonkin.
{TM1SubsetToSet([Period].[Period], "Current Period", "public").Item(0)}
Don't forget the curly braces. Or:
Head( {TM1SubsetToSet([Period].[Period], "Current Period", "public")}, 1 )
The value of 1 can be left out if you want, Head will return the first element if that argument is not provided.
{Filter( TM1SubsetAll( [Dates] ), [Dates].CurrentMember.Properties("Serial date") < 20635)}.Item(0)
When you add the curly braces, the tuple becomes a set:
{{Filter( TM1SubsetAll( [Dates] ), [Dates].CurrentMember.Properties("Serial date") < 20635)}.Item(0)}
{Filter( {TM1SubsetAll( [Scenario] )}, Val([Scenario].CurrentMember.Properties([cube].([dim1].[member], [dim2].[member]))) = 1)}
This expression will look for a Scenario where the Flag attribute is 1, knowing that the cube stores Flag as a string value.
{TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 0)}
SubsetCreatebyMDX( 'Subset by measure', '{TM1SubsetToSet([Account], [Measure].CurrentMember.Name, "public")}', 'Account' );
Attach the subset called 'Subset by measure' to the view for that row dimension. Make sure the measures are positioned in the titles section of the view. When you now
switch from 1 measure to another, the rows will update on the fly ! Great trick to make your reports truly dynamic. It avoids either creating 5 reports, or asking the
user to selecting 1 of 5 subsets in the rows - you don't want to ask that from your user base.
Of course, the 5 subsets in the row dimension should exist (as public subsets but you are free to add whatever custom logic you need for the MDX definition of the subsets. Very useful !
Elements at different levels
{TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 0)}
{Filter( [Project_type].Members, [Project_type].CurrentMember.Properties("ELEMENT_LEVEL")="0")}
{TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 1,2,3 )}
Alternatively: {Filter( TM1SubsetAll( [Project_type] ), StrToValue([Project_type].CurrentMember.Properties("ELEMENT_LEVEL")) >= 1 AND StrToValue([Project_type].CurrentMember.Properties("ELEMENT_LEVEL")) <= 3 )}
StrToValue can be swapped for Val as well.
This version avoids having to specify the levels in between. Granted, it's a longer syntax but probably better than listing for example 1,2,3 and even more (1,2,3,4,5,6,7,8, ...). Or you could use the Intersect of 2 sets: 1 set for at least level 1 and 1 set for at most level 3. The advantage with listing the desired levels, is that you can add other levels too and the order does not need to be respected: {TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 3,6,1 )} is the same as: {TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 1,3,6 )}
pDim = 'Customer';
LEVEL_MIN = 1;
LEVEL_MAX = 6;
vMDX = 'Filter( TM1SubsetAll( [%pDim%] ), StrToValue([%pDim%].CurrentMember.Properties("ELEMENT_LEVEL")) >= %LEVEL_MIN%';
vMDX = vMDX | ' AND StrToValue([%pDim%].CurrentMember.Properties("ELEMENT_LEVEL")) <= %LEVEL_MAX% )';
vMDX = Expand( 'Filter( ' | vMDX | ', [%pDim%].CurrentMember.Parent.Name = "" )' );
AsciiOutput( 'test.txt', vMDX );
Filter( TM1SubsetAll( [Period] ), Val( Left( [Period].CurrentMember.Name, 4 )) = 2025 )
Thanks (again) George Tonkin, and he continued to add the following. What seems to be very useful is you can use Val against a numeric attribute e.g.:
Filter( TM1SubsetAll( [Scenario] ), Val( [Scenario].CurrentMember.Properties("Flag")) = 1 )
For C levels and other N levels where flag was never specified and shows a 0, these do not result in an error like StrToValue and the need to use Iif to trap for a null and set it to 0 before converting. Changing the above MDX to filter on a value of 0 returns those members either set to 0 or never set to begin with.
{ Except( TM1SubsetAll( [Project_type] ), { TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 0) } )}
Order( TM1SubsetAll( [Product]), Val([Product].CurrentMember.Properties("ELEMENT_LEVEL")), Bdesc)
This could help you for instance in case of duplicate alias values. You could add a numeric suffix to elements with the same alias value, whereby the elements appear in the Data tab of the process based on their level in the dimension. Then, incrementing numbers for the suffix will go along with the levels as they decrease.
{Except( Descendants( [Client].[Running projects] ), Descendants( [Client].[Paid projects] ), ALL )}
{ Except( Hierarchize( TM1SubsetAll( [Project_type] )), { TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 0) } )}
{[Project_type].Members}
HOWEVER, TM1SubsetAll and Members do not necessarily lead to the same output ! Members can have more elements in the resulting subset, since it counts unique paths towards an element whereas TM1SubsetAll only takes unique elements. So: if you use certain elements multiple times in the dimension, it can lead to different results.
{ Except( TM1FilterByLevel( TM1SubsetAll( [Work_Customers] ), 0), {[Work_Customers].[Office]} ) }
Please refer to below for a discussion of the Subset function that can also exclude for example the first element of a set.
 Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Ordinal < 2 )
Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Ordinal < 2 )Intersect( Descendants( [Period_MDX].[All months]), [Period_MDX].[Year].Members )
Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Name = "Year" ), OR:
Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Name = "level001" )
Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Ordinal = [Period_MDX].[Year].Ordinal ), OR:
Filter( Descendants( [Period_MDX].[All months]), [Period_MDX].CurrentMember.Level.Ordinal = [Period_MDX].[level001].Ordinal )
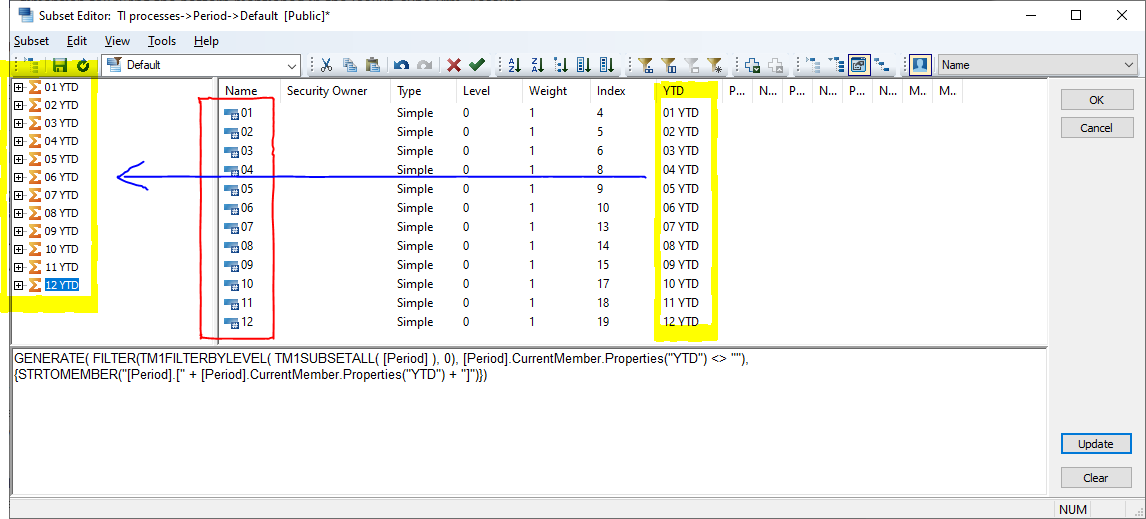
For this to work, you should refer to the picture below for the level names:
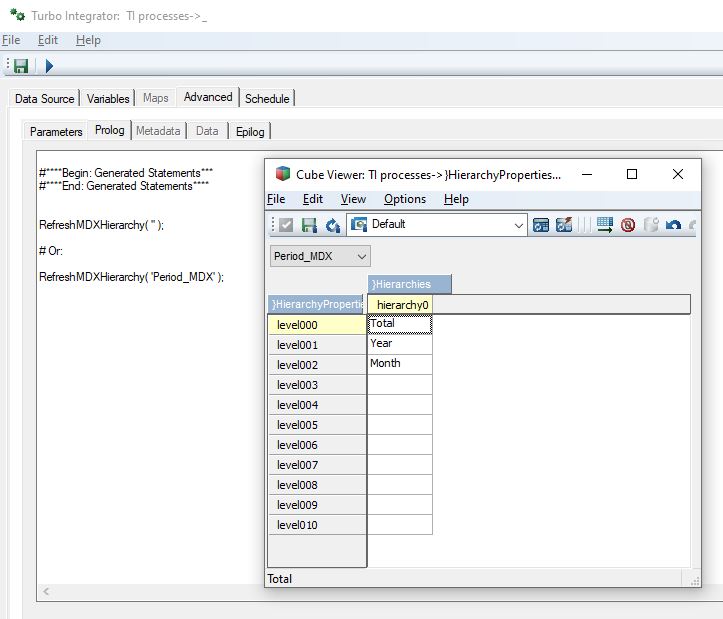
Run the little TI process to update the hierarchies in the different dimensions (every time you are done making changes to that particular cube) !
Note also this possibility:
Filter( TM1DrillDownMember( TM1SubsetAll([Period_MDX]), ALL, Recursive), StrToValue([Period_MDX].CurrentMember.Properties("LEVEL_NUMBER")) = 1)
It starts at the top of the hierarchy and goes down a level with every number increased. Level 0 equals root members, level 1 the children of the root members, etc.
Lastly, "LEVEL_NAME" exists too. You may want to use it to filter on named levels defined in the }HierarchyProperties cube.
Filter( {TM1SubsetAll( [model] )}, [model].CurrentMember.Properties("PARENT_LEVEL") > "0" )
This returns all members without root members which would be Parents with a level of 0.
Sorting
{TM1Sort( TM1FilterByLevel( TM1SubsetAll( [Project_type] ), 0), Asc)}
Next to Sort, Order is also supported.
Order( {[Month].Members}, [Month].CurrentMember.Properties("Short monthnr"), Asc)
Short monthnr is an alias in this case.
{Order( TM1SubsetAll( [Month] ), [Month].CurrentMember.Properties("Long name"), Asc)}
{Order( TM1SubsetAll( [Product_Group] ), Val([Product_Group].CurrentMember.Properties("Sort order")), Asc )}
For instance, to filter out elements based on an attribute value: Filter( TM1SubsetAll( [Company].[Company]), [Company].[Company].CurrentMember.Properties("Size") = "Large" )
rather than:
Filter( TM1SubsetAll( [Company].[Company]), [Company].[Company].[Size] = "Large" )
IMPORTANT note on using numeric attributes in MDX !
Refer to the same discussion and a peek into future TM1 versions/changes. A.o., the idea is to use the optional TYPED parameter in the Properties function. Like that, the Properties function will not automatically convert to a text value (with side effects as a result of that). For this to work, IBM are working on this.
In TM1 V11 (11.8.019 and later) using TYPED in TM1 works. It also works in V12. In earlier V11 versions it throws a syntax error.
Filter( TM1SubsetAll( [Company].[Company]), [Company].[Company].CurrentMember.Properties("Number of employees", TYPED) > 100 )
Like this, the attribute "Number of employees" is allowed to be a string attribute and calculations are still possible. This is great as it gives us a solution to also properly resolving numeric attribute values without a CAST function. If you still want a safe solution for all V11 and V12 installs, the only way which works in all versions is a cell value query to the attribute cube itself.
Filter( TM1SubsetAll( [Company].[Company]), [}ElementAttributes_Company].([}ElementAttributes_Company].[Number of employees]) > 100 )
Filter( TM1SubsetAll( [Customer]), [Customer].CurrentMember.Properties("Segment") = "4.000000" )
Using older ambiguous notation (you should avoid potential conflicts between elements / subsets / attributes):
Filter( TM1SubsetAll( [Customer]), [Customer].[Segment] = 4 )
{Order( Descendants( [Client].[Paid projects] ), [Client].CurrentMember.Properties("Description"), Asc)}
{[Customer].[Total Customer]} + {Order( Filter( TM1FilterByLevel( Descendants( [Customer].[Total Customer]), 0), [Sales].([Product].[Total Product], [Year].[Total Year], [Period].[Total Period], [Currency].[EUR], [Sales_Msr].[Sales]) < -0.01 OR [Sales].([Product].[Total Product], [Year].[Total Year], [Period].[Total Period], [Currency].[EUR], [Sales_Msr].[Sales]) > 0.01 ), [Sales].([Product].[Total Product], [Year].[Total Year], [Period].[Total Period], [Currency].[EUR], [Sales_Msr].[Sales]), Desc) }
Note how we have 3 times the same information in the expression regarding element selections. For some dimensions, it would be better to leave them out and use the DefaultMember property in the }HierarchyProperties control cube.
{Filter( TM1FilterByLevel( TM1SubsetAll( [Customer] ), 0), IIF( [SalesCube].([Product].[Total Product], [Year].[Total Year], [Sales_Msr].[Sales USD]) < 0, -1*[SalesCube].([Product].[Total Product], [Year].[Total Year], [Sales_Msr].[Sales USD]), [SalesCube].([Product].[Total Product], [Year].[Total Year], [Sales_Msr].[Sales USD])) > 10000 )}
Declan Rodger posted an alternative with an MDX view query in this discussion topic. Also, Hubert Heijkers commented there about other functions that are supported in other IBM tools and that could one day be supported in TM1/Planning Analytics.
{StrToMember( "[Sales_Msr].[" +
Case [Sys_Param].([Sys_Param].[Sales amounts abbreviation], [Sys_Param_Msr].[String])
When 'K' Then 'Value (K)'
When 'M' Then 'Value (M)'
Else
'Value'
End
+ "]" )}
{StrToMember ( "[Dim_Measure].[" + IIF ( [Scenario].CurrentMember.Name = "Elem1", "MeasureA", "MeasureB" ) + "]")}
{StrToMember ( "[Dim_Measure].[" + CASE [Scenario].CurrentMember.Name WHEN "Elem1" then "MeasureA" WHEN "....." then "Measure..." ELSE "MeasureB" END ) + "]")}
Link
{{TM1SubsetAll( [Version] )}.Item(Iif(TM1TupleSize({Filter( {TM1SubsetAll( [Weekly Performance] )}, [Weekly Performance].[enddate] < 20635)}.Item(0)) = 0, 2, 3))}
Thank you Trevor MacPherson
Note that relying on indexes is not always the best idea as they can change.
Order( Order( Order( {[Employee].Members}, [Employee].CurrentMember.Properties("Department"), Asc), [Employee].CurrentMember.Properties("Age"), Asc), [Employee].CurrentMember.Properties("Salary"), Asc)
This expression sorts employees first on their Salary, then on their Age, finally on their Department. Thank you Keith Would for sending an email on this expression. Note that using BAsc and BDesc is probably preferred over Asc and Desc, respectively. When using Order, Asc/Desc and BAsc/BDesc are for different cases. BAsc/BDesc breaks down any hierarchies before sorting, Asc/Desc sorts within hierarchies.
Keith also pointed out that you can sort on the concatenated attribute values by using, for example:
Order( Order( {[Employee].Members}, [Employee].CurrentMember.Properties("Department")+[Employee].CurrentMember.Properties("Age"), Asc), [Employee].CurrentMember.Properties("Salary"), Asc)
Order( TM1FilterByLevel( TM1SubsetAll( [Month].[Month] ), 0), Val( Iif([Month].[Month].CurrentMember.Properties("Seq No") = "", "9999" /* Default Value */, [Month].[Month].CurrentMember.Properties("Seq No")))), BAsc)
But probably best to use the attributes cube:
Order( TM1FilterByLevel( TM1SubsetAll( [Month] ), 0), [}ElementAttributes_Month].( [}ElementAttributes_Month].[Seq No] ), BAsc )
Descendants and Ascendants
{Descendants([FIN_Account].[EBIT]) }
{Except( Descendants([FIN_Account].[EBIT]), {[FIN_Account].[EBIT]} )}
{Descendants([FIN_Account].[EBIT], 0, AFTER )}
gives us the same result, and thereby providing the names of dimension and element only once. AFTER omits the parent element. Other flags exist, such as: SELF, AFTER, BEFORE, BEFORE_AND_AFTER, SELF_AND_AFTER, SELF_AND_BEFORE, SELF_BEFORE_AFTER, LEAVES.
For more information, refer to: Microsoft documentation
{Descendants([FIN_Account].[EBIT], 99, LEAVES )} PAW generates this kind of expression, at least in version 2.0.82, as reported by George Tonkin end of 2023. Whether the arbitrary distance value of 99 is sufficient/necessary/efficient, is up to your judgment. An alternative is an explicit calculation of levels: [FIN_Account].[FIN_Account].Levels.Count
At any rate, the expression will include consolidated elements without children, should they exist in the hierarchy.
Descendants([FIN_Account].[FIN_Account].[EBIT], 2)
It follows that Descendants with a distance of 1 just returns the immediate children: Descendants([FIN_Account].[FIN_Account].[EBIT], 1)
Adding the flag to only return the level 0 elements becomes easy and at the same time very useful: Descendants([FIN_Account].[FIN_Account].[EBIT], 2, LEAVES)
Descendants([FIN_Account].[FIN_Account].[EBIT], 3, BEFORE)
{LastPeriods( 3, StrToMember( "[Cm_YearMonth].[" + [Sys_CFG].([Sys_CFG_Environment].[Current], [Sys_CFG_Input].[Value], [Sys_CFG_Msr].[Reporting Year Month]) + "]"))}
sYearMonth = CellGetS( 'Sys_CFG', 'Current', 'Value', 'Reporting Year Month' );
SubsetCreateByMDX( vSubset, '{LastPeriods( 3, {[Cm_YearMonth].[' | sYearMonth | ']} )}' );
{StrToMember( "[Cm_YearMonth].[" + [Sys_CFG].([Sys_CFG_Environment].[Current], [Sys_CFG_Input].[Value], [Sys_CFG_Msr].[Reporting Year Month]) + "]"), Descendants( StrToMember( "[Cm_YearMonth].[" + [Sys_CFG].([Sys_CFG_Environment].[Current], [Sys_CFG_Input].[Value], [Sys_CFG_Msr].[Reporting Year]) + "]"), 1 )}
Here, "Reporting Year" and "Reporting Year Month" are populated in a general configuration cube. They could be data input, populated with a TI process, or rules-calculated with whatever logic you see fit. For now, it would be 2025-01 and 2025, for instance.
Additionally, you could sort the children alphabetically based on an attribute.
More information on how to filter dimension members using cube values will follow below.
The dimension Cm_YearMonth (here) contains totals for the years (yyyy) and descendants for the periods (yyyy-mm). By taking out the parameter 1 at the end of the MDX, you will have the current month, followed by the year total, followed by the 12 months of the year. Hence, if you link that value of 1 to a selection for the user, the user can easily toggle between data including or excluding the sum total of the year.
If you include quarters and/or half years in the same rollup, that distance parameter of 1 should be set accordingly to exclude these intermediate levels. Or, leave them in for more detailed analyses over the time periods.
Instead of the comma to separate the 2 sets in the MDX above, the most likely alternative is the Union function with the ALL argument.
Union operates on only 2 sets, contrary to the original Microsoft implementation.
{TM1FilterByLevel( Descendants([FIN_Account].[EBIT]), 0)}
or:
{TM1FilterByLevel( TM1DrilldownMember( [FIN_Account].[EBIT], ALL, Recursive), 0)}
You can easily sort the returned elements (here, ascending):
{TM1Sort( TM1FilterByLevel( Descendants([FIN_Account].[EBIT]), 0), Asc)}
Leaving out the filter by level will return the consolidated element(s) as well. So, Descendants and TM1DrilldownMember both include the parent element that was drilled upon.
SubsetCreateByMDX( vSubset, '{TM1FilterByLevel( Descendants( [Month].[' | pMonth | ']), 0)}', 'Month' );
{ Except( TM1FilterByLevel( TM1SubsetAll( [Fct_Product] ), 0), Descendants( [Fct_Product].[My consolidated product] ) )}
{Except( Descendants([Customer].[Total Customer]), {TM1FilterByLevel( Descendants([Customer].[Total Customer]), 0 )} )}
{TM1FilterByLevel( Union( Descendants( [FIN_Account].[EBIT] ), Descendants( [FIN_Account].[Taxes] )), 0)}
{Union( {FIN_Account.[EBIT]}, TM1FilterByLevel( Descendants(FIN_Account.[EBIT]), 0) )}
or:
{FIN_Account.[EBIT], TM1FilterByLevel( Descendants(FIN_Account.[EBIT]), 0) }
Note: The Union function can be shortened to the + operator (an element is listed only once):
{FIN_Account.[EBIT]} + {TM1FilterByLevel( Descendants(FIN_Account.[EBIT]), 0)}
or, now EBIT is at the bottom of the list, the Order of the elements in the expression is retained left to right:
{{TM1FilterByLevel( Descendants(FIN_Account.[EBIT]), 0)}, FIN_Account.[EBIT] }
Next to Union, Intersect is also supported. Sidenote: if you want to avoid the removal of duplicate elements, use a comma instead of a plus sign. Example: [Fct_Product].[A], [Fct_Product].[B], [Fct_Product].[C], TM1FilterByLevel( Descendants([Fct_Product].[C]), 0)}
{StrToMember( "[Cm_Scenario].[" + [Fn_Rp_General_Config].( [Cm_Scenario].[Actual], [Fn_Rp_General_Config].[Planning Scenario], [Fn_Rp_General_Config_Msr].[Value] ) + "]")} + {TM1Sort( TM1FilterByLevel( TM1SubsetAll( [Cm_Scenario] ), 0 ), Asc )}
TM1Sort( Union( TM1FilterByPattern( TM1FilterByLevel( TM1SubsetAll( [St_Account] ), 0), "6*"), TM1FilterByPattern( TM1FilterByLevel( TM1SubsetAll( [St_Account] ), 0), "7*") ), Asc )
Except( TM1FilterByLevel( TM1SubsetAll( [St_Account] ), 0), TM1SubsetToSet( [PL_Account], "P&L Accounts" ))
Notice that the subset "P&L accounts" should exist too: we filter out elements that appear in a certain subset.
{Ascendants([Fct_Customer].[111522])}
Note that only the parents in the first rollup in the hierarchy are retrieved, which can often be a limitation.
Hierarchize( [Fct_Customer].[111522].Ancestors )
Hierarchize( Ascendants( [Fct_Customer].[111522] ))
{Hierarchize( Generate( Filter( Distinct({[Cost Center].[Cost Center].Members, {[Cost Center].[Cost Center].[Total Cost Center^Cost Centers]}}), [Cost Center].[Cost Center].CurrentMember.Name = "Marketing"), Ascendants([Cost Center].[Cost Center].CurrentMember)))}
Now that's a mouthful ! First, we take all members of the dimension and out of all those members, we take the set of Distinct members. Next, we filter that resulting list on the elements whose name is Marketing - it could well be multiple elements. For instance, Marketing could be used 4 times in the hierarchy, with different parent sets. Generate is then used to "generate" all ascendants elements of each of the 4 element instances. To format the result a bit, we throw an Hierarchize against it and we nicely see the rollup structures from 4 elements all the way to their top parents.
Filter( Except( TM1SubsetAll( [Rp_Cost_Element] ), TM1FilterByLevel( TM1SubsetAll( [Rp_Cost_Element] ), 0 )), TM1TupleSize( Intersect({[Rp_Cost_Element].[INPUT Sales third parties]}, Descendants([Rp_Cost_Element].CurrentMember)).Item(0)) > 0)
Item(0) gives us the first element in the result set.
Thank you Ty Cardin
Put differently, to collect all ascendants of an N-Element right to the root of the dimension tree: Filter( TM1SubsetAll( [Dimension] ), TM1TupleSize( Intersect( {[Dimension].[N-Element]}, Descendants( [Dimension].CurrentMember )).Item(0)) > 0 )
{Tail( {Ascendants([Fct_Customer].[111522])}, 1 )}
In TM1 an element may have multiple parents within a hierarchy so if there are multiple parent branches you may need the intersect between the ancestors and all top node elements in the dimension:
{Intersect( {Ascendants([Fct_Customer].[111522])}, {Filter( {TM1SubsetAll( [Fct_Customer] )}, [Fct_Customer].CurrentMember.Parent.Name = "")})}
I would understand it if you prefer levels (0 is the highest level in a dimension/hierarchy): {Intersect( {Ascendants([Fct_Customer].[111522])}, [Fct_Customer].Levels(0).Members )}
{ToggleDrillState( {[Account].[6].Children}, {[Account].[63]} )}
The consolidated element '6' in the Account dimension is drilled into and gives consolidated elements ( not expanded) of '60', '61', '62', ... What ToggleDrillState does is still drill into an element, in this case the '63' consolidation.
This leaves the possibility to expand on the second set - it could be a filter in itself:
{{ToggleDrillState( {[Account].[6].Children}, {Filter( {[Account].[6].Children}, [Account].CurrentMember.Name < "63" ) } )}
The above works as long as all such children can be compared in an alphanumeric way. Should we want to compare in a numeric way, we need to convert strings to numbers:
{ToggleDrillState( {[Account].[6].Children}, {Filter( {[Account].[6].Children}, StrToValue( "0" + [Account].CurrentMember.Name ) <= 21 ) } )}
Note that I applied an interesting trick: I use a prefix of '0' for those element names that are not really numbers !
{TM1ToggleDrillState( {[Account].[6].Children}, {[Account].[63]}, EXPAND_BELOW, RECURSIVE )}
An alternative for TM1ToggleDrillState is Hierarchize( ..., POST ). Yes, Hierarchize has an optional second argument !
Filter( Filter( TM1SubsetAll( [Customer] ), [Customer].CurrentMember.Parent.Name = "" ), Count( Filter( Descendants([Customer].CurrentMember), Instr( [Customer].CurrentMember.Name, [Customer].CurrentMember.Parent.Name ) = 0 )) > 0 )
The interesting part to notice as well is that [Customer].CurrentMember can be different following the context where it is evaluated.

More on hierarchical structures
{[Project_type].[All Types].Children}
{[Project_type].[All Types].Children(0)}
Here we ask for the first child, as the index is zero-based. The 5th child is done with Children(4). It is a shorthand notation for the Item function.
DrillDownLevel( {[Project_type].[All Types]} )
TM1DrillDownMember( {[Project_type].[All Types]}, ALL )
Descendants([Project_type].[Project_type].[All Types], 3, BEFORE)
{ Descendants([Fct_Assumption].[Total Assumption]) } + { DrillDownLevel( [Fct_Assumption].[Subtotals]) }

DrilldownLevelTOP( {[Project_type].[All Types]}, 3 )
Here we grab the parent element (All Types) and its first 3 immediate children.
DrilldownLevelBOTTOM will be easy to understand now.
DrillUpLevel( Descendants( [Cm_Date].[YTD] ), [Cm_Date].Levels(2) )
An entire structure of consolidated elements starting with YTD can be expanded, but only up to the desired level. Not all the way down the hierarchy. An example of not specifying the level, whereby TM1 will stop above the lowest level present in this set:
DrillUpLevel( Descendants( [Cm_Date].[YTD] ))
DrillDownMember( {[Month].[Q2]}, {[Month].[Total Year].Children} )
will leave us with the element Q2 as well as its 3 children (Apr, May, Jun), provided the element "Total Year" contains Q2 as an immediate child.
Moreover, if "Total Year" contains 4 elements for the quarters, then this MDX:
DrillDownMember( {[Month].[Q2], [Month].[Total Year]}, {[Month].[Total Year].Children} )
Will return Q2, Apr, May, Jun and the "Total Year". The latter is just returned, not drilled on, because it is not part of the second set.
A 3rd argument called RECURSIVE allows to do the drill more than once, actually until no more drilling is possible or none of the resulting elements is part of the second set.
DrillDownMember( {[Month].[Q2]}, {[Month].[Total Year].Children}, RECURSIVE )
In this case, it won't change the result.
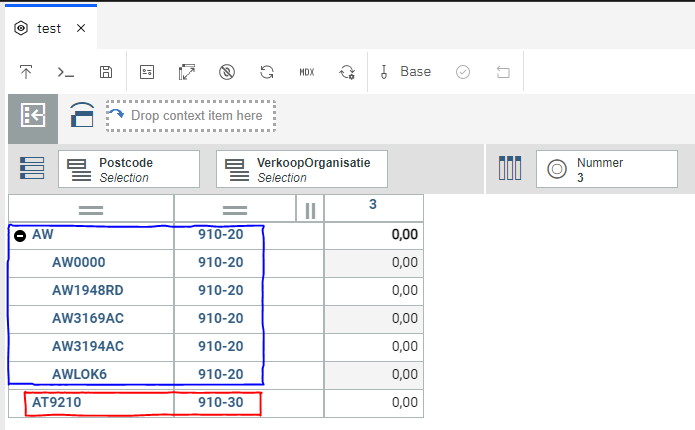
SELECT {[Nummer].[3]} ON 0, DrilldownMember( {([Postcode].[AW],[VerkoopOrganisatie].[910-20]), ([Postcode].[AT9210],[VerkoopOrganisatie].[910-30])}, { [Postcode].[AW] }) ON 1 FROM [test]
This is an example of an (asymmetric) MDX view. The possibilities are endless !
{[Month].[Q2].FirstChild}
… will return Apr. LASTCHILD gives us Jun.
{[Month].[Q2].FirstSibling}
… will return Q1. LASTSIBLING gives us Q4.
{[Month].[Q1].Siblings}
… will return the 4 quarters.
{Filter( TM1SubsetAll( [Month] ), IsSibling( [Month].CurrentMember, [Month].[Q1] ) )}
… will return the same 4 quarters, but in larger dimensions, loops over elements for filtering can degrade the performance.
{Head( {[Month].[Q1].Children}
… will return Jan.
{Subset( TM1SubsetAll( [Month] ), 2, 3 )}
… will return 01, 02, 03 in my case since the Month dimension has elements (based on their index) of Total, Q1, 01, 02, 03, Q2, 04, …
We take 3 elements (the last argument) as of spot 3 since the argument of 2 is a 0-based index. Should we omit the value of 3 then we get all elements starting at the 3rd element until the last element.
Subset( DrillDownLevel( Head( TM1SubsetToSet([Month], "Current YTD", "public" ))), 1 )
The catch is near the end of the expression. 1 means that we start returning elements as of the 2nd element (it's 0-based). Then we omit the 3rd argument such that TM1 will happily give us all following elements. The end result is that, while DrillDownLevel gives us the consolidation and its immediate children, we can exclude the consolidation without any difficulty.
Subset( Filter( [SCH_Location].Levels(0).Members, [SCH_Location].CurrentMember.Properties("ELEMENT_TYPE") = "3" ), x-1, 1 )
{Filter( {TM1SortByIndex( TM1FilterByLevel( TM1SubsetAll([Month].[Month]), 0 ), Asc)}, (StrToValue([Month].[Month].CurrentMember.Properties("ELEMENT_INDEX")) ≥ StrToValue([Month].[Month].[Feb].Properties("ELEMENT_INDEX")) ) AND (StrToValue([Month].[Month].CurrentMember.Properties("ELEMENT_INDEX")) ≤ StrToValue([Month].[Month].[May].Properties("ELEMENT_INDEX")) ) )}
Here I retrieve Feb, Mar, Apr, May. Obviously other strategies exist but think about other, more difficult, dimensions too. For instance (but relying on elements having a good index): all projects in a project dimension between project X and project Y.
The MDX uses the index number of the elements. When you need this in a TI process, it's probably easier use a Dimix() in the MDX instead of the second ELEMENT_INDEX formula. For instance: StrToValue("' | NumberToString( vIndex_1 ) | '") with vIndex_1 being an element index and likewise for vIndex_2 as upper limit.
Easier alternatives can exist, including the : operator, but beware of cases where you think selecting certain elements and in the end you end up with nothing or other elements.
Filter( Order( TM1FilterByLevel( TM1SubsetAll([Time].[Time]), 0), [Time].[Time].CurrentMember.Properties("Code"), Asc), [Time].[Time].CurrentMember.Properties("Code") ≥ "' | pStart_Month | '" AND [Time].[Time].CurrentMember.Properties("Code") ≤ "' | pEnd_Month | '" )
Code as the alias contains values such as 202501, 202502, etc.
{Tail( {[Month].[Q1].Children}
… will return Mar.
{[Month].[Q3].Lag(2)}
… will return Q1.
[Fiscal Period].[2025.01]:StrToMember( "[Fiscal Period].[" + [Sys_CFG].([Sys_CFG_Input].[Value], [Sys_CFG_Msr].[Current Period]) + "]").Lag(1)
January 2025 is hard-coded but you could make this dynamic. We need a cube called Sys_CFG, as well as the few other components that you can see in the MDX.
You can get more alternative expressions and food for thought here.
{[Month].[Q3].Lead(1)}
… will return Q4.
Lag(1) is equivalent to LEAD(-1), since the functions are inverse. Both functions can take on positive, negative or 0 values.
{[Month].[Q3].PrevMember}
… will return Q2.
Generate({[Cm_YearMonth].[Cm_YearMonth].[2025]}, {[Cm_YearMonth].[Cm_YearMonth].CurrentMember,[Cm_YearMonth].[Cm_YearMonth].CurrentMember.PrevMember,[Cm_YearMonth].[Cm_YearMonth].CurrentMember.PrevMember.PrevMember})
This statement will return 2025, 2024, 2023, as for instance the 3 most recent years. 2025 could be sourced from a parameter cube.
Obviously, you could also store the previous years in the parameter cube (manual entry, rules-calculated, TI, whatever) but this example takes away the need to do so. Or the members could be obtained from attribute values.
Very important ! We are taking the previous or next members in a hierarchy. TM1 respects the levels in the hierarchy. So, even if the hierarchy as in my case, contains rollups for years with 12 month children underneath each year: the previous element at the year level goes to last year, not last month. But the previous element at the month level goes to the last month. No additional coding should be done in case of year crossings or just make sure that the previous element of 2025-01 is not 2025 (index-wise, it is, though).
{TM1Sort( LastPeriods( 3, [Cm_YearMonth].[2025]), Desc )}
This statement will also return 2025, 2024, 2023 (respecting the levels in the hierarchy) when 2025 is the base year.
The current year and the 2 next years will then be:
{LastPeriods( -3, [Cm_YearMonth].[2025])}
This statement will return 2025, 2024, 2023 when 2025 is the base year.
The function name is a bit misleading and not indicative of the fact that it works in any hierarchy - not just hierarchies with periods. The next team member name in a hierarchy, the previous 10 cost centers or revenue accounts, the following 30 product names, whatever.
{Cousin( [Month].[10], [Month].[Q3] )}
… will return 07. Assumed is a structure of 4 quarters, with children 01-02-03, 04-05-06, 07-08-09, 10-11-12. Month 10 is similar to month 07 if you apply the parent element of Q3. TM1 recognizes Q4 as the parent of month 10 and then jumps back to Q3 (what we asked for) and singles out its second child. Both months are the second month within the respective quarter. It's probably not a bad idea to qualify month 10 more as: [Month].[Q4^10] in case month 10 is used multiple times in the same dimension.
{OpeningPeriod([Month].[Month].[Level 0],[Month].[Month].[2025])}
… will return 202501 (in my example dimension of concatenated years and months). 202501 is the first child (descendant) below 2025, which cuts the level of "Level 0" that I used as the name.
This function (like a number of others) was brought to my attention by George Tonkin, many thanks for that.
{ClosingPeriod([Day].[Day].[Level 0],[Day].[Day].[2025])}
… will return 2025-12-31 (in my example dimension of all days > years > quarters > months > days). Note that there are 2 intermediate levels in the dimension (quarter and month) that are not important here and will be skipped). Level 0 descendants of 2025 will be used, then the last element is used. Alternatively, we could look at Descendants and Tail but it's good to see other ways of achieving the same result. Even more, Descendants will not always lead to the same result as a level.
The last day in the dimension will then be: {ClosingPeriod([Day].[Day].[Level 0],[Day].[Day].[All dates])} or {Tail( TM1FilterByLevel( Descendants( [Day].[Day].[All dates]), 0))}
{OpeningPeriod([Account].[Account].[Level 0],[Account].[Account].[Personnel costs])} or {Head( TM1FilterByLevel( Descendants( [Account].[Account].[Personnel costs]), 0))}
If you stick it in the Generate function, nice results will come out :-) A simple list of input accounts based on your high-level buckets.
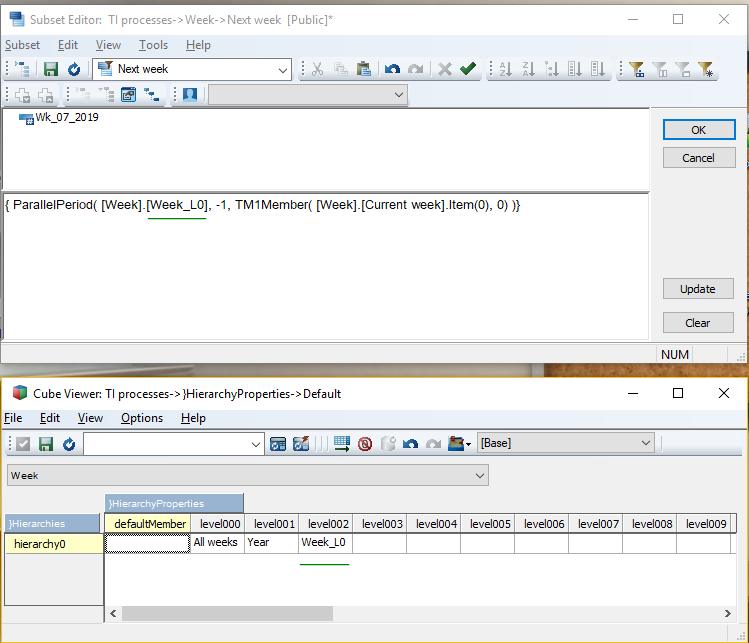
{ ParallelPeriod( [Week].[Week_L0], -1, TM1Member( [Week].[Current week].Item(0), 0) )}
ParallelPeriod is actually to be understood as a lag. With a positive value, you go backwards in the dimension, index-wise. Please check out the function LastPeriods as well, elsewhere on this page.
Note that I also use the Week_L0 'level' element in the }HierarchyProperties cube. Pay attention to use e.g. 'Week_L0' if you fill out the cube cell, however, if you did not specify anything you should use level002 (within the given dimension/hierarchy). You need to refresh when edits are made to this cube, but other than that, it's a good way to make your TM1 models more dynamic and 'readable' by humans. Refreshing can be done using the TI function RefreshMDXHierarchy( '' ); for all dimensions / hierarchies, or RefreshMDXHierarchy( 'dimension or hierarchy' ); for a given dimension/hierarchy.
I used the dimension for 'Week' as an example but the above function also works on dimensions that do not have a time concept, like companies.
Notice the defaultMember element too, we will discuss it later on in the document.
For more information on Named levels, refer to: IBM documentation. The idea is also that statements like [Customer].[Country].Members or [Customer].[Country].Members work, certainly in for dimensions/hierarchies that are not ragged - here, we have a Customer dimension where a rollup exists for customers into countries (the result is the list of distinct countries).
{ TM1Member( [Week].[Current week].Item(0), 0).NextMember }
Please note that TM1Member is probably not your safest bet. In Planning Analytics there have been cases where it can lead to issues, depending on the usage and situation at hand of course. Use with caution. The bottom line is that it seems that this function, when used in other MDX, is stripped and Planning Analytics reverts to the definition/logic contained in it.
{TM1Rollup( {[Month].[Jan]}, {[Month].[Jan]} )}
returns the parents of the month of January in the Month dimension. This expression mimicks the rollup button in the Subset Editor, by the way. It can be similar to a loop over Elpar from 1 to ElparN.
You can use Except( TM1Rollup( {[Month].[Jan]}, {[Month].[Jan]} ), {[Month].[Jan]} ) to leave out the level 0 element from the result set.
{Ancestor([Rp_Account].[600000], 0)},
{Ancestor([Rp_Account].[600000], 1)},
{Ancestor([Rp_Account].[600000], 2)},
{Ancestor([Rp_Account].[600000], 3)}, …
will return the element itself (0), then the parent (1), grandparent (2), parent of the grandparent (3).
In case an element has multiple parents, for instance immediate parents, then you will only receive one of the parents. It is not necessarily giving you the parent with the smallest index in the hierarchy. It's probably the parent that is part of the first rollup of the hierarchy.
Also consider the use of the function Ascendants elsewhere in this document, for similar use-cases.
{Ancestor([Rp_Account].[600000], [Rp_Account].[Level000])} such that you can ask for an element higher up in the dimension that is cut by some level.
{Ancestors([Rp_Account].[600000], 1)}, {Ancestors([Rp_Account].[600000], 2)}, {Ancestors([Rp_Account].[600000], 3)}, …
The same comments as to Ancestor apply here.
{Filter( TM1SubsetAll( [Rp_Account] ), IsAncestor( [Rp_Account].CurrentMember, [Rp_Account].[600000] ))}
Note that performance can be degraded with the Filter function, as it needs to loop over items. In addition, the function will not yield all hierarchy elements that have the said element as an ancestor.
{LastPeriods( 3, [Month].[Q3])}
… will return Q1, Q2, Q3.
Please note that LastPeriods is not restricted to time dimensions. It can be utilized in a similar fashion on any dimension irrespective to what element names are used.
{[Month].[Q3].Level.Members}
… will return Q1, Q2, Q3, Q4.
PeriodsToDate( [Manad].[Level000], TM1Member( Tail( Filter( [Manad].[Total Year].children, [cubename].([z.TestRowEntryList].[R01]) > 0), 1).Item(0), 0))
This solution works if the Level000 name is adequate (it can be swapped for something meaningful). It stands for the parent level of the elements to be selected. Look at the }HierarchyProperties cube and a TI process with the command RefreshMDXHierarchy.
PeriodsToDate( [Manad].[Total Year].Level, TM1Member( Tail( Filter( [Manad].[Total Year].children, [cubename].([z.TestRowEntryList].[R01]) > 0), 1).Item(0), 0))
The PeriodsToDate formula can also be used in dimensions (hierarchies) that are not dealing with Time or Periods. So Accounts, Cost Centers, Companies, ... though of course it still has to make sense.
{[Month].[Month].[Jan]:[Month].[Month].[Oct]}
… will return Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct.
-
Please note the following requirements (if not satisfied, an empty set is returned and/or an error):
- Both elements should exist in the hierarchy and be at the same level in the hierarchy
- Index-wise, no dimension elements at a different level, can be between the 2 listed elements
Using a filter could be an option too, for instance in a dimension with countinuous dates:
Filter( TM1FilterByLevel( TM1SubsetAll( [Time_Day] ), 0 ), [Time_Day].CurrentMember.Properties("Name") ≥ "20250801" AND [Time_Day].CurrentMember.Properties("Name") < "20250831" )
TM1SortByIndex( TM1Member( TM1SubsetToSet([Months].[Months], "subset1", "public").Item(0), 0):TM1Member( TM1SubsetToSet([Months].[Months], "subset1", "public").Item(0), 0).Lead(5), Asc)
Here we retrieve a number of months, based on the contents of a public subset called subset1 (its first element). That element and the next 5 elements are taken, 6 months in total. Note that this technique is very powerful in continuous time dimensions, crossing years. Your 12 month moving windows becomes child's play !
Also note that the previous expression can be greatly simplified to:
TM1SortByIndex( LastPeriods( -6, TM1Member( TM1SubsetToSet( [Months], "subset1", "public").Item(0), 0 )), Asc)
Finally on this topic, consider "jumping" to a different month by advancing 5 months:
{TM1Member( TM1SubsetToSet( [Months], "subset1", "public").Item(0), 0).Lead(5)}
Planning Analytics hierarchies
Since some time now we can use hierarchies in IBM Planning Analytics. Any dimension can become a container of 1 or more so called hierarchies. These hierarchies can be used in cube views and reports in an orthogonal fashion, such that one can analyze the data in a much richer way than before. The so-called Leaves hierarchy is automatically maintained by the software, containing a copy of all level 0 elements in the entire dimension (over hierarchies). Here is a dynamic subset on the }Dimensions dimension to identify all dimensions that contain hierarchies: Filter( TM1SubsetAll( [}Dimensions] ), Instr( [}Dimensions].CurrentMember.Lead(1).Name, [}Dimensions].CurrentMember.Name + ":" ) = 1 )
Except( TM1FilterByLevel( TM1SubsetAll( [Customer].[Leaves]), 0 ), Generate( TM1FilterByLevel( TM1SubsetAll( [Customer].[Customer]), 0 ), Filter( TM1FilterByLevel(TM1SubsetAll([Customer].[Leaves]) , 0), [Customer].[Leaves].CurrentMember.Name = [Customer].[Customer].CurrentMember.Name )))
Submitted by George Tonkin, thanks for this.
Union and Intersect
{Union( {[Account].[Earnings Before Taxes] }, {[Account].[Subset Exp Above] })}
Here the subset 'Subset Exp Above' is a second (public) subset on the same dimension: { Except( {TM1DrillDownMember( {[Account].[Earnings Before Taxes] }, ALL, RECURSIVE )}, { [Account].[Earnings Before Taxes] })}
Thanks to Paul Simon for posting.
Update by Lotsaram (October 2021) in the same topic, with a simpeler syntax: {TM1ToggleExpandMode( {[Account].[Earnings Before Taxes]} + {[Account].[Subset Exp Above]}, EXPAND_ABOVE)}
{TM1ToggleExpandMode( {[Account].[Earnings Before Taxes]}, EXPAND_ABOVE)}
Union( TM1FilterByPattern( TM1FilterByLevel( Descendants( [St_CostCenter].[FP] ), 0 ), "613194?00*" ), TM1FilterByPattern( TM1FilterByLevel( Descendants( [St_CostCenter].[Plant Manager] ), 0 ), "613194?00*" ), ALL )
{Intersect( Filter( TM1SubsetAll( [Month] ), [Filter].([Filter].[FilterOrder]) <> 0), Descendants(Month.[Q1]) )}
Filter( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location] ), Count( Intersect( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location]), {[CostCenter].[CostCenter].CurrentMember}, All )) > 1 )
Notice the use of the argument All. If we were to leave it out, like we do in other examples on Intersect, then the MDX engine will first remove duplicate elements. Of course this is not what we want in this case. If All is specified, the Intersect function intersects nonduplicated elements as usual, and also intersects each duplicate in the first set that has a matching duplicate in the second set.
Filter( TM1FilterByLevel( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location] ), 0 ), TM1TupleSize( Intersect( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location] ), {[CostCenter].CurrentMember}, All ).Item(1)) = 1 )
This expression finds the leaf elements that have multiple parents in a given rollup (see the example given for cost centers).
The result is for instance 1 element name (like Cost Center ABC) but it appears twice in the subset. This is because the Distinct function looks at the Member Unique Name (MUN). Those 2 results could then be expanded to for instance their parent elements (ancestors) to quickly analyze where the double counting affects the totals and/or to understand where it went wrong.
Alternatively, you remove the duplicates in Excel and work from that list of really unique elements. Why did I write Excel instead of PAW ? PAW has a button to remove duplicate elements in the Set editor. However, that button works on the MUNs and effectively adds the Distinct function that we added ourselves too. Hence, this will not be the solution to your problem. To still have a solution in PAW using MDX, read the following paragraph.
Generate( Filter( TM1FilterByLevel( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location] ), 0 ), TM1TupleSize( Intersect( Descendants( [CostCenter].[CostCenter].[Total Cost Center By Location] ), {[CostCenter].CurrentMember}, All ).Item(1)) = 1 ), { StrToMember( "[CostCenter].[CostCenter].[" + [CostCenter].[CostCenter].CurrentMember.Name + "]" ) })
See: this page
{Intersect( TM1SubsetToSet( [Account], "Cost accounts" ), TM1SubsetToSet( [Account], "Filter by level 0" ) )}
The above expression would be more efficient with TM1FilterByLevel, however, but this is just an illustration.
vDim = 'Account';
vSubset1 = 'Cost accounts';
vSubset2 = 'Filter by level 0';
vSubset3 = 'Input cost accounts';
# Create MDX
vMdx = '{Intersect( TM1SubsetToSet( [' | vDim | '], "' | vSubset1 | '" ), TM1SubsetToSet( [' | vDim | '], "' | vSubset2 | '" ) )}';
# Or, in a more readable format:
vMdx = Expand( '{Intersect( TM1SubsetToSet( [%vDim%], "%vSubset1%" ), TM1SubsetToSet( [%vDim%], "%vSubset2%" ) )}' );
SubsetCreateByMDX( vSubset3, vMDX, vDim );
Hierarchize( TM1SubsetAll( [Project] ), POST )
However, it is not really an Expand above. Even though the children are shown below the parents, when you expand a parent, it will expand downwards ! (hence, in the usual fashion of expanding totals). This means that you will first see the children, then the total and when expanding the totals, again the children. I don't have an immediate use-case for it but let's keep in mind for when it's needed.
Cube values
{Filter( TM1FilterByLevel( TM1SubsetAll( [BS_Account] ), 0), [BalanceSheet].([FIN_Year].[2025],[FIN_Period].[P07],[FIN_Scenario].[Actual],[BS_Measures].[Amount]) <> 0)}
If we do not specify an element in a dimension of the cube, TM1 will use the element with the lowest index of all elements at the highest level in the dimension, unless we specify a defaultMember in the }HierarchyProperties control cube. So watch out and make sure this is what you need. Note that we also have a DEFAULT_HIERARCHY property in the }DimensionProperties cube.
Note that the user must have (READ) access to the cube that is used in the lookup, just as to the elements.
The defaultMember property of a dimension/hierarchy can be retrieved with:
{ [SalesPerson].DefaultMember }
The }HierarchyProperties control cube is useful to turn your TM1 models into more dynamic models which are 'readable' by developers that come after you !
Topcount, bottomcount, topsum, bottomsum, toppercent and bottompercent could be done in a similar fashion:
{TopCount( TM1FilterByLevel( TM1SubsetAll( [SalesPerson] ), 0), 5, [Sales].([Sales_Measures].[Amount]))}
A practical use-case for Order and TopCount:
{Order( TopCount( TM1FilterByLevel( TM1SubsetAll( [SalesPerson] ), 0), 10, [Sales].([Sales_Measures].[Amount])), [Sales].([Sales_Measures].[Amount]), BDesc)} Statements like TopCount or TopSum can be recorded with the interface, as well as sorting elements alphabetically:
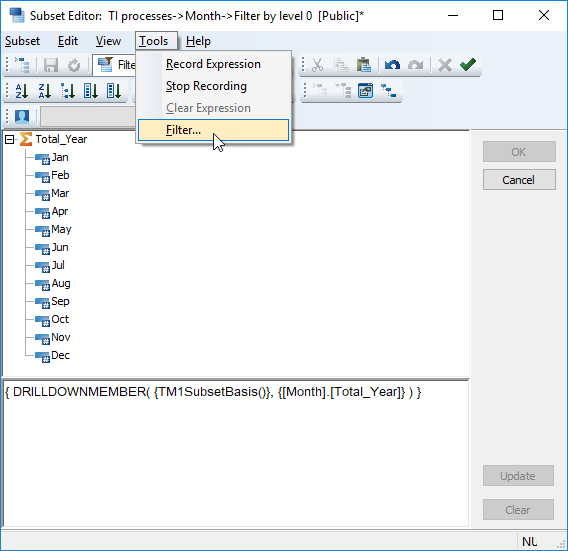


In the above expression please take out the dreaded TM1SubsetBasis (cf. supra). By the way, I discovered a nice trick to quickly see in which cubes a dimension is used: Go to the dimension's Subset Editor, then Tools > Filter... and the dropdown will show you the cubes containing the dimension.
In Excel reports, the TM1RPTFILTER function can be used as well, to drive TopCount, BottomSum and similar results.
As we noticed earlier, the HEAD function can be used to limit a subset to, say, its first 5 elements.
{Filter( TM1FilterByLevel( TM1SubsetAll( [Month] ), 0), [Currency Rate].([Currency].[USD], TM1Member([Year].[Current Year].Item(0),0), [Scenario].[Actual], [Measure Currency].[Average rate] ) < 0.9 )}
Here, "Current Year" is a public subset in the Year dimension. Its first and only element is used to filter out the average rate in the cube.
Filter( {TM1FilterByLevel( {TM1SubsetAll( [Customer] )}, 0)}, [Invoice].(TM1Member([Time].[Invoice Month].Item(0),0),[Invoice_measures].[Outstanding balance]) > 0 )
Filter({TM1FilterByLevel( {TM1SubsetAll( [Customer] )}, 0)}, [Invoice].([Invoice_measures].[Outstanding balance]) > 0 )
is equal to:
Filter({TM1FilterByLevel( {TM1SubsetAll( [Customer] )}, 0)}, [Invoice].[Invoice_measures].[Outstanding balance] > 0 )

{Head( Filter( [Data Entry Row].[All Rows].Children, [Entry Cube].([Version].[Forecast], [Entry Cube Measure].[Entry]) = "" ), 5 )}
Important notes:
- This method requires a refresh of the sheet/dashboard to get the extra rows to appear (but not after every row that was input).
- For the HEAD function to work properly the element ordering and leveling in the dimension is important !
- If your Entry measure is of type Numeric, replace the double quotes with a 0 in the expression.
- You could still add [Data Entry Row].CurrentMember, in the Filter expression but you don't have to
Thank you Lotsaram
It is crucial to know that, you will receive an error on the MDX in these cases:
- the attribute value is empty
- the attribute value is not empty but it does not exist in that measures dimension ProfitLoss_Msr
Filter( Filter( TM1SubsetAll( [Account] ), [Account].CurrentMember.Properties("Msr") <> "" ), [ProfitLoss].([Time].[Current month], StrToMember( "[ProfitLoss_Msr].[" + [Account].CurrentMember.Properties("Msr") + "]")) > 100000 )
But the MDX expression becomes longer. Working around condition 2 is very difficult. Probably not worth it and a TI process might be a better option (to populate a static subset). Also see: this thread.
Head( TM1SortByIndex( TM1FilterByLevel( TM1SubsetAll( [LineNr] ), 0), Asc), Iif( [Activity_Input].([YearMonth].CurrentMember, [Consultant].CurrentMember, [LineNr].[1], [Msr].[Nr of lines] ) < 10, 10, [Activity_Input].([YearMonth].CurrentMember, [Consultant].CurrentMember, [LineNr].[1], [Msr].[Nr of lines] ))))
Should you want to bring over the value of 10 to a parameter cube:
Head( TM1SortByIndex( TM1FilterByLevel( TM1SubsetAll( [LineNr] ), 0), Asc), Iif( [Activity_Input].([YearMonth].CurrentMember, [Consultant].CurrentMember, [LineNr].[1], [Msr].[Nr of lines] ) < [z_PARAM].([z_PARAM].[Minimum number of lines], [VAR_TXT].[NUM_VAR1]), [z_PARAM].([z_PARAM].[Minimum number of lines], [VAR_TXT].[NUM_VAR1]), [Activity_Input].([YearMonth].CurrentMember, [Consultant].CurrentMember, [LineNr].[1], [Msr].[Nr of lines] ))))
{TM1FilterByPattern( TM1SubsetAll([Account_PL]), [Prm_Account].([Prm_Account_dim1].[Pattern], [Prm_Account_Msr].[Text]))}
{TM1FilterByPattern( TM1SubsetAll([Account_PL]), LookUpCube ( "Prm_Account", "([Prm_Account_dim1].[Pattern], [Prm_Account_Msr].[Text])" ) )}
… will filter all elements in the Account_PL dimension following the pattern mentioned in the lookup cube Prm_Account.
Furthermore, LookUpCube could also retrieve longer (or entire) MDX expression from a cube cell, next to element names or certain selections. For example:
{StrToMember( LookUpCube( "Sys_CFG", "[Sys_CFG].[MDX current month], [Sys_CFG_Msr].[Text]" ))}
whereby the target string cell in the system configuration cube holds: [Period].[June]
Or:
{StrToSet( LookUpCube( "Sys_CFG", "[Sys_CFG].[MDX for active users], [Sys_CFG_Msr].[Text]" ))}
whereby the target string cell in the system configuration cube holds: TM1Sort( Filter( TM1SubsetAll( [}Clients] ), [}ClientProperties].([}ClientProperties].[STATUS]) = "ACTIVE" ), Asc )
Imagine the possibilities when rules are going to dynamically piece together MDX statements for a given context and that MDX is picked up in a dynamic way in a subset ? Highly dynamic and customized picklists, anyone ? :-)
{TM1FilterByPattern( TM1SubsetAll([Month]), [Prm_Finance].([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text]))}
This can be done, however, with similar syntax:
{Union( TM1FilterByPattern( TM1SubsetAll([Month]), [Prm_Finance].([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text])), TM1FilterByPattern( TM1SubsetAll([Month]), "YTD_" + [Prm_Finance].([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text])))}
Alternatively you can again use the LookUpCube function:
{Union( TM1FilterByPattern( TM1SubsetAll([Month]), LookUpCube( "Prm_Finance", "([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text])" )), TM1FilterByPattern( TM1SubsetAll([Month]), "YTD_" + LookUpCube( "Prm_Finance", "([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text])" )))}
Syntax 1 definitely has my vote, since it is somewhat shorter, but most of all because we avoid the double quote character ".
You can of course use Turbo Integrator to create/maintain subsets but honestly, this MDX-based dynamic solution certainly has merits, and is something I would add to TM1 models to increase the usefulness to the TM1 user community.
You could use a wildcard to cut down on the length of the expression, but beware that this could lead to additional elements in the subset which might not be wanted:
{TM1FilterByPattern( TM1SubsetAll([Month]), "*" + [Prm_Finance].([Prm_Fin_Param].[Month of close], [Prm_Finance_Msr].[Text]))}
Finally, and apologies for the spoiler to the Generate function which is discussed below:
Generate( Filter( TM1FilterByLevel( TM1SubsetAll( [Period] ), 0), [Period].CurrentMember.Properties("YTD") <> ""), {StrToMember( "[Period].[" + [Period].CurrentMember.Properties("YTD") + "]")})
Here we filter out all lowest-level Period elements that have an attribute value (textual) for their YTD name. Then the MDX returns those YTD elements instead of the level 0 elements. Think of Generate as swapping elements for the result of a subquery that uses each element (in turn). More on this below !
{StrToMember( "[Rp_Year].[" + [Rp_Irp_Parameter].([Rp_Scenario].[Actual], [Rp_Irp_Parameter].[Reporting Year], [Rp_Irp_Parameter_Msr].[Value]) + "]") }
{StrToMember( "[Period].[" + [Period].[Jul 2025].Properties("Prior Period") + "]")}
July 2025 is hard-coded but you could make this dynamic.
{Filter( TM1FilterByLevel( TM1SubsetAll([Rp_Year]), 0 ), [Rp_Year].CurrentMember.Name = [Rp_Irp_Parameter].([Rp_Scenario].[Actual], [Rp_Irp_Parameter].[Reporting Year], [Rp_Irp_Parameter_Msr].[Value]))}
{StrToMember( "[Rp_Year].[" + LookUpCube( "Rp_Irp_Parameter", "[Rp_Scenario].[Actual],[Rp_Irp_Parameter].[Reporting Year],[Rp_Irp_Parameter_Msr].[Value]" ) + "]") }
{NameToSet("[Rp_Year].[2025]")}
To point to the element 2025 within the "All years" hierarchy (not PA-hierarchy but traditional hierarchies): {NameToSet("[Rp_Year].[All years^2025]")}
{LastPeriods( 4, StrToMember( "[Year].[" + [System].([System_Prm].[Year],[System_Msr].[Text]) + "]") )}
Here we want to retrieve the year from the system cube along with its 3 previous years. Make sure the Year dimension indexes are correct.
{Filter( TM1FilterByLevel( TM1SubsetAll( [Period] ), 0), [Periods 2D].( StrToMember( "[Year].[" + [System].([System_Prm].[Year], [System_Msr].[Text]) + "]")) > 0 )}
Hereby, we filter elements in the dimension 'Period' based on data in the cube 'Periods 2D'. In that cube, we select cells based on a year that is stored in the cube 'System'.
{Filter( {Filter({TM1SubsetAll([Project])}, [Project].[Primary Site] <> "" )}, [z_Security_Site].( StrToMember( "[}Clients].[" + USERNAME + "]"), StrToMember( "[Site].[" + [Project].[Primary Site] + "]"), [z_Security_Control_Measure].[Write_Flag]) > 0 )}
{StrToMember( MemberToStr( [Project].[001] ) )}
gives us the element 001. MemberToStr gives us here the string: "[Project].[001]".
StrToMember( "[Period].[2025-05].NextMember")
can return the next member in the dimension, 2025-06 in this case. An alternative expression could be:
{StrToMember( "[Period].[2025-05]").NextMember}
or simply:
[Period].[2025-05].NextMember
{StrToMember( "[Day].[2025-06].FirstChild.Lag(1)")}
to get the last day of the month of May 2025 (admittedly, LastChild of 2025-05 is far easier but it's just for illustration purposes).
It reminds me of the Excel function: =Date(2025, 6, 0 ). "Day 0" of any month gives you the last day of the previous month (even going back to December 31 of last year if needed) !
{StrToMember( "[Product].[ABC]").FirstChild}
StrToSet( "{Filter( {[Year].Members}, " + Iif( Count( {Filter( {[Year].Members}, [YM].([Year].CurrentMember, [Maand].[tekst]) = "test" )} ) > 0, "[YM].([Year].CurrentMember, [Maand].[tekst]) = """ + "test" + """", "[Year].CurrentMember.Name = """ + "total" + """" ) + ")}" )
If certain elements satisfy the condition of having a certain input text in a 2D cube, then take that list. If not, take a dummy element. Code adapted from Declan Rodger's posting here. Added benefit: this example teaches you the functions IIF and COUNT (see below).
StrToSet( "{Filter(Descendants([z_test].[Total)," + Iif( Count( {Filter(Descendants([z_test].[Total), [z_test].[Type] = 'A')}) > 0, "[z_test].[Type] = 'A'", Iif( Count( {Filter(Descendants([z_test].[Total]), [z_test].[Type] = 'B')}) > 0, "[z_test].[Type] = 'B'", "[z_test].[Type] = 'C'" )) + ")}" )
{StrToSet( SetToStr( [Project].[All projects].Children ) )}
gives us the children of "All projects" in the Project dimension. SetToStr gives us here the string: "{[Project].[001], [Project].[002], [Project].[003]}" if we limit ourselves to 3 projects.
Note that even if the set only returns 1 element, the name of the element will still be wrapped in curly braces {}:
{[Project].[001]}
{Filter( {Filter({TM1SubsetAll([Project])}, Not( IsEmpty( [Project].[Primary Site] )) )}, [z_Security_Site].( StrToMember( "[}Clients].[" + USERNAME + "]"), StrToMember( "[Site].[" + [Project].[Primary Site] + "]"), [z_Security_Control_Measure].[Write_Flag]) > 0 )}
The function IsNull, a valid function in MDX-land, does not seem to be implemented in TM1.
Filter( TM1FilterByLevel( TM1SubsetAll( [CostCenter] ), 0), Instr([Prm_CostCenter].([CostType].[No type], [Prm_CostCenter_Msr].[Manager Name]), 'jones' ) > 0)
{Filter( TM1FilterByLevel( TM1SubsetAll( [Customer] ), 0), [Sales].([Sales_Msr].[Amount]) > Avg( TM1FilterByLevel( TM1SubsetAll( [Customer] ), 0), [Sales].([Sales_Msr].[Amount] )))}
Just like Avg, you can also use (among others): Sum, Min, Max, Median, Aggregate, Var.
Filter( TM1FilterByLevel(TM1SubsetAll([Time]), 0), [Balance].([Funds].[KDB]) > Avg( TM1FilterByLevel(TM1SubsetAll([Time]), 0), [Balance].([Funds].[KDB])))
Aggregate( TM1SubsetToSet( [Product], 'Best products' ))
{[Customers].[All customers]} + {Order( Filter( TM1FilterByLevel( TM1SubsetAll( [Customers] ), 0), [Sales].([Sales_Measures].[Amount]) <> 0 ), [Sales].([Sales_Measures].[Amount],[Sales_Year].[2025]), Asc) }

Suppose that each region/country holds the name of the (consolidated) model that can be sold in the region/country:
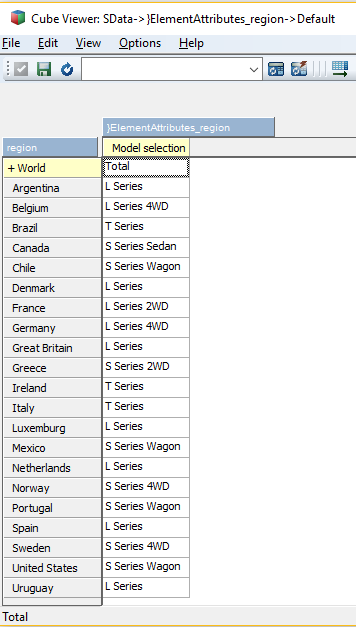
Then we can get the relevant consolidated model element based on the region selection in the titles section:

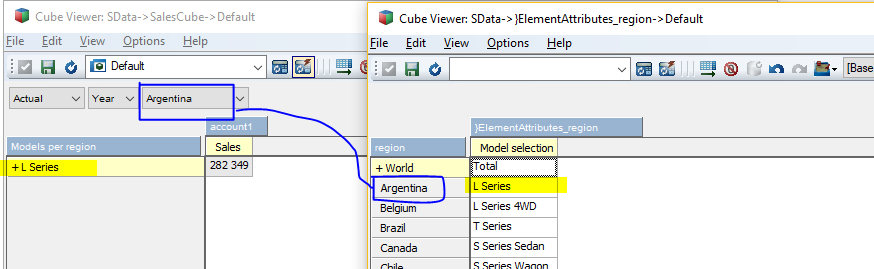
1. The MDX is like this:
{StrToMember( "[model].[" + [region].CurrentMember.Properties("Model selection") + "]")}
2. Alternatively: We can also use the Filter function as with Declan Rodger here
Filter( TM1SubsetAll( [model] ), [model].CurrentMember.Name = [region].[Model selection])
3. This is somewhat longer, in case the attribute name could/would coincide with an element name in the dimension:
Filter( TM1SubsetAll( [model] ), [model].CurrentMember.Name = [region].CurrentMember.Properties("Model selection"))
If we want to have the consolidated element and all its lowest-level descendants (for data entry for example):
{StrToMember( "[model].[" + [region].CurrentMember.Properties("Model selection") + "]")} + TM1Sort( TM1FilterByLevel( Hierarchize( Descendants( {StrToMember( "[model].[" + [region].CurrentMember.Properties("Model selection") + "]")} )), 0 ), Asc )

For budget entry we can then have a template with companies as a title selection and in the rows we have the main product category for that company, as well as the level 0 descendants:
{StrToMember( "[Rp_ProductGroup].[" + [Rp_Company].CurrentMember.Properties("Product Group parent member") + "]")} + TM1Sort( TM1FilterByLevel( Hierarchize( Descendants( {StrToMember( "[Rp_ProductGroup].[" + [Rp_Company].CurrentMember.Properties("Product Group parent member") + "]")} )), 0 ), Asc )
TM1Sort( TM1FilterByLevel( Descendants( {StrToMember( "[Rp_ProductGroup].[" + [Rp_Company].[C90290].Properties("Product Group parent member") + "]") }] ), 0 ), Asc )
How do we generate the subsets in 1 TI process ? There are a lot of interesting learning tips in this code so please be sure to look in detail, if needed. A double Expand function is just 1 area of interest.
# Process to (re)generate subsets on the product dimension, where every company has its own (dynamic) subset of products sold
sDim_Comp = 'Rp_Company';
sDim_Prod = 'Rp_ProductGroup';
sAttr_For_Prod = 'Product Group parent member';
# MDX query to get the products linked to a company
sMDX = 'TM1Sort( TM1FilterByLevel( Descendants( {StrToMember( "[%sDim_Prod%].[" + [%sDim_Comp%].[%sElem_Code%].Properties("%sAttr_For_Prod%") + "]") }] ), 0 ), Asc )';
# loop over companies and (re)generate the dynamic subsets
c = 1;
While( c <= Dimsiz( sDim_Comp ) );
sElem_Name = Dimnm( sDim_Comp, c );
sElem_Code = Attrs( sDim_Comp, sElem_Name, 'Code' );
If( sElem_Code @<> '' );
If( Ellev( sDim_Comp, sElem_Name ) = 0 );
If( Elisanc( sDim_Comp, 'Total Company', sElem_Name ) = 1 );
vSubset = '}Products_' | sElem_Code;
If( SubsetExists( sDim_Prod, vSubset ) = 0 );
SubsetCreate( sDim_Prod, vSubset );
EndIf;
SubsetMDXSet( sDim_Prod, vSubset, Expand( sMDX ));
SubsetAliasSet( sDim_Prod, vSubset, 'Description' );
EndIf;
EndIf;
EndIf;
c = c + 1;
End;
{DrillDownLevel( {[Account].[Net result]} + {Filter( {[Account].[Net result].Children}, [PnL].([Scenario].[Actual], [Period].[2025], [Currency].[Local Currency], [Company].[3200], [PnL_Msr].[Amount] ) <> 0 )} )}
StrToMember( "[Period].[" + IIF( [User-Navigation].( StrToMember( "[}Clients].[" + UserName + "]"), [User-Navigation Measures].[Period]) <> "", [User-Navigation].(StrToMember( "[}Clients].[" + UserName + "]"), [User-Navigation Measures].[Period]), "<default>") + "]")
However, George Tonkin (again him!) found a much neater and shorter solution with a different function, CoalesceEmpty:
StrToMember( "[Period].[" + CoalesceEmpty( [User-Navigation].(StrToMember( "[}Clients].[" + UserName + "]"), [User-Navigation Measures].[Period]), "<default>" ) + "]")
Filtering on attributes
{Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].CurrentMember.Properties("Type") = "PL")}
{Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].[Type] = "PL")}
The drawback is that this syntax could be ambiguous, if 'Type' is an element or subset or attribute of the dimension/hierarchy. The previous syntax is more robust and therefore better.
{Filter( {[version].members}, [version].[created by user] = StrToMember( "[}Clients].[" + UserName + "]").Properties('}TM1_DefaultDisplayValue'))}
Double quotes around }TM1_DefaultDisplayValue are allowed too.
Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].CurrentMember.Properties("MEMBER_CAPTION") = "Hotel costs")
The Caption attribute can be an alias or a regular text attribute. When it is an alias, at most 1 element will be returned. When it is a text attribute, more than 1 element can be returned.
Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].CurrentMember.Properties("MEMBER_NAME") = "Hotel costs")
TM1SortByIndex( Filter( TM1FilterByLevel( TM1SubsetAll( [Article] ), 0 ), [}ElementAttributes_Article].([}ElementAttributes_Article].[Quantity]) = 0 ), Asc)
Here we filter out articles that have a Quantity equal to 0 and sort the resulting articles (if any).
Filter( TM1FilterByLevel( TM1SubsetAll([Periods-Months]), 0), [Periods-Months].[TM1 Last Day Serial Date] >= StrToValue( StrToMember( "[Periods-Months].[" + [Prm_Finance].( [Prm_Fin_Param].[Value], [Prm_Finance_Msr].[Text] ) + "]" ).Properties("TM1 Last Day Serial Date")))
See here.
{Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].[Type] = [Prm_Account].([Prm_Account].[Parameter_Value],[Prm_Account_Measures].[Account type]))}
{Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].[Conversion] = 1)}
{Filter( TM1SubsetAll( [FIN_Account] ), [FIN_Account].[Description] <> "" )}
{Filter( TM1SubsetAll( [FIN_Account] ), Instr( [FIN_Account].[Description], "Amortization" ) > 0 )}
Note that the MDX function Instr is case-sensitive in this form but it can be made case-insensitive too with an additional optional argument of value 1: {Filter( TM1SubsetAll( [FIN_Account] ), Instr( [FIN_Account].[Description], "Amortization", 1 ) > 0 )} In that case, TM1 will convert both earlier arguments to lowercase and then perform the comparison. This means that adding 1 is a more elegant solution then us having to add the LCase or UCase function to both arguments. More information can be obtained here and also here
{ Filter( {TM1SubsetAll([Dim_Currency])}, [}ClientProperties].( StrToMember( "[}Clients].[" + USERNAME + "]"), [}ClientProperties].[currency]) = [Dim_Currency].CurrentMember.Name )}
- Dim_Currency is the dimension of currencies, it could be anywhere in the view, active form, ...
- currency is an attribute added to the }ClientProperties cube, it should match the currencies in the dimension Dim_Currency
{Filter({[Organisation].Members}, [Organisation].CurrentMember.Name = StrToMember ( "[}Clients].[" + UserName + "]" ).Properties("Department"))}
{TM1FilterByLevel( Descendants( Filter( TM1SubsetAll( [CostCenter] ), [CostCenter].[Overhead CC] = "Y" ) ), 0)}
{Filter( TM1SubsetAll( [CostCenter] ), NOT Iisleaf( [CostCenter].CurrentMember ))}
{Filter( TM1SubsetAll( [CostCenter] ), [CostCenter].CurrentMember.Properties("CHILDREN_CARDINALITY") = "3" )}
{Filter( Filter( TM1SubsetAll( [CostCenter] ), [CostCenter].CurrentMember.Properties("ELEMENT_TYPE") = "3" ), [CostCenter].CurrentMember.Properties("CHILDREN_CARDINALITY") = "0" ) }
TM1Sort( Generate( Filter( TM1FilterByLevel(TM1SubsetAll([Product]), 0), [Product].CurrentMember.Properties("Profit Center") <> "" ), { StrToMember( "[Product].[" + Iif( StrToMember( "[Product].[" + [Product].CurrentMember.Properties("Profit Center") + "]").FirstChild.Properties("Local / Global") <> [Product].CurrentMember.Properties("Local / Global"), [Product].CurrentMember.Name, "# Product" ) + "]" )} ), Asc )
Well done, George Tonkin !
Double lookups
{ StrToMember( "[Period].[" + StrToMember( "[Period].[" + [Period].[Jul 2025].Properties("Prior Period") + "]").Properties("Prior Period") + "]") }
I am not saying that is the best method or even the only one. You could store the attribute values differently and do 1 lookup instead of 2. Of you could use the Lag function.
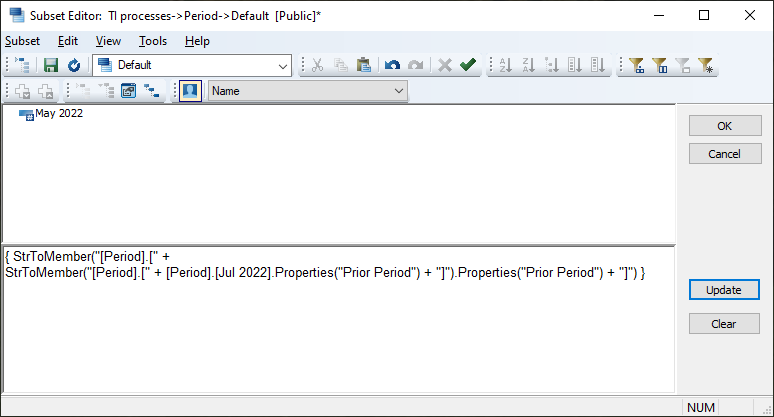
{StrToMember( "[Period].[" + StrToMember( "[Year].[" + [Sys_CFG].([Sys_CFG_Environment].[Current_Env], [Sys_CFG_Input].[Value], [Sys_CFG_Msr].[Selected year]) + "]").Properties("Best month") + "]")}

Filtering over dimensions
{Filter( TM1SubsetAll( [St_Account] ), Instr( [St_Account].CurrentMember.Name, [Mp_Std_Company].([Mp_Std_Company_Msr].[Company]) ) = 1 )}
- St_Account is the dimension of accounts in the rows.
- Mp_Std_Company is the cube where the companies are mapped (a 2D cube with companies and a measure called "Company"). Below, China Guangzhou is mapped in the lookup cube to "C010", which filters the prefix in the accounts.

This is based on the information in this topic.
{TM1Sort( Filter( TM1FilterByLevel( TM1SubsetAll( [St_Account] ), 0), Instr([Mp_Std_Account].([Mp_Std_Account_Msr].[Reporting Account]), "710000" ) = 1 ), Asc )}
Here we generate a list of source accounts that are mapped to account 710000. Combine it with the OR function for greater flexibility.
Filtering with wildcards
{TM1FilterByPattern( TM1FilterByLevel( TM1SubsetAll( [FIN_Account] ), 0), "613?2*")}
{ Filter( TM1SubsetAll( [FIN_Account] ), ( ([FIN_Account].[Type] = "PL" AND [FIN_Account].[Conversion] = 1) OR ([FIN_Account].[Description] <> "" ) ) ) }
TM1Sort(Except({ Filter(TM1FilterByLevel(TM1SubsetAll([_S-Product]), 0), ( [_S-Product].CurrentMember.Properties("AAA") = "" OR [_S-Product].CurrentMember.Properties("BBB") = "" OR [_S-Product].CurrentMember.Properties("CCC") = "" OR ( [_S-Product].CurrentMember.Properties("FFF") = "XYZ" AND [_S-Product].CurrentMember.Properties("GGG") = "")) AND Instr(1, [_S-Product].CurrentMember.Properties("Status"), "DO NOT DELETE", 1) = 0 )}, {[_S-Product].[#Product],[_S-Product].[No Product]}), Asc)
{TM1FilterByPattern( TM1FilterByLevel( TM1SubsetAll( [FIN_Account] ), 0), "*Maintenance*", "Description")}
Simply add the attribute name as an extra argument to the function. Note that the lookup is a case-insensitive one, so Maintenance yields the same hits as mAinTeNANcE. This is probably what most users require such that they do not have to remember or guess the exact spelling. For a case-sensitive search, consider Instr. Note that Filter and Instr can be much slower than. TM1FilterByPattern. Certainly as of April 2023, when it was reported that IBM apparently improved the function.
{Filter( {TM1SubsetAll( [Fct_Country] )}, [Fct_Country].CurrentMember Is [Fct_Country].[BE] )}
Here I filter out the element that is logically equal to the BE element in the dimension Fct_Country. Of course, the expression above is not very optimized. We should not 'loop' over all elements to identify a certain element, since we can pick the said element in a direct way (see other syntax examples), like: {[Fct_Country].[BE] )}. However more advanced examples could be thought of.
More on sorting
{ Hierarchize( TM1SubsetAll( [CostCenter] ))}
{TM1SortByIndex( TM1SubsetAll( [PL_Account] ), Asc)}
Alternatively:
{Order( TM1SubsetAll( [PL_Account] ), [PL_Account].CurrentMember.Properties("Index"), Asc)}
Or:
{Order( TM1SubsetAll( [PL_Account] ), [PL_Account].CurrentMember.Properties("MEMBER_ORDINAL"), Asc)}
Both submitted by George Tonkin, thanks.
Order( TM1SubsetAll( [PL_Account] ), [PL_Account].CurrentMember.Properties("MEMBER_CAPTION"), Asc)
vDim = 'PL_Account';
vSubset = 'tmp';
vSubset_tmp = vSubset | '_xyz';
SubsetCreate( vDim, vSubset_tmp, 1 );
vMDX = '{TM1SubsetToSet([' | vDim | '].[' | vDim | '], "' | vSubset | '", "public")}';
SubsetMDXSet( vDim, vSubset_tmp, vMDX );
vMDX = 'Order( {TM1SubsetToSet([' | vDim | '].[' | vDim | '], "' | vSubset_tmp | '", "public")}, [' | vDim | '].[' | vDim | '].CurrentMember.Properties("MEMBER_CAPTION"), Asc )';
SubsetMDXSet( vDim, vSubset, vMDX );
SubsetMDXSet( vDim, vSubset, '' );
SubsetDestroy( vDim, vSubset_tmp );
{TM1Sort( Filter( TM1FilterByLevel( TM1SubsetAll( [Time] ), 0), [Time].CurrentMember.Name <= "' | pLastMonthOfActuals | '" ), Asc)}
or (Code is an alias on the Time dimension):
{TM1Sort( Filter( TM1FilterByLevel( TM1SubsetAll( [Time] ), 0), [Time].[Code] <= "' | pLastMonthOfActuals | '" ), Asc)}
or (selecting a range of months, possibly spanning multiple years):
{TM1Sort( TM1FilterByLevel( [Time].[202001]:[Time].[202009], 0), Asc)}
{TM1Sort( Filter( Filter( TM1FilterByLevel( TM1SubsetAll( [Product] ), 0), [Rpt_Sales].([Year_Month].[Total 2025], [Region].[Total Region], [Sales_Msr].[Revenue]) <> 0), [Product].[Sales_Rep] = "" ), Asc )}
Note that this kind of dynamic subset is an ideal candidate to present in a view to users - one can see immediately for which products the attribute should be completed.
Generate
{Generate( {TM1FilterByLevel( {TM1SubsetAll( [Customers] )}, 1)}, TopCount( Descendants([Customers].CurrentMember, 1), 1, Act_Sales.([Act_Sales_Msr].[Revenue])))}
Please note that with Generate, the second clause is the operative dimension in which you create the subset.
Generate( Order([Month_YTD_FY_Offset].[Total Year].Children, [Month_YTD_FY_Offset].CurrentMember.Properties("FY order"), Asc), Descendants( {StrToMember( "[Month_YTD_FY_Offset].[" + [Month_YTD_FY_Offset].CurrentMember.Name + "]")}))
A numeric attribute is used to capture the order of the months in the fiscal year. The output is summarized for clarity, not all days are shown.

gives:

{Generate( Filter( TM1SubsetAll( [Employee] ), [Employee Planning].([Scenario].[RP 2025], [Employee Planning Measures].[Manager ID]) <> ""), {StrToMember( "[" + [Employee Planning].([Scenario].[RP 2025], [Employee].CurrentMember, [Employee Planning Measures].[Manager ID]) + "]")})}
{Generate( TM1FilterByLevel( Descendants( {[Account].[6]} ), 1 ), Union( [Account].CurrentMember, TopCount( Descendants([Account].CurrentMember, 1), 3, [Rpt_PL].([Company].CurrentMember, [Scenario].CurrentMember, [Year].CurrentMember, [Period].CurrentMember, [Currency].[Group Currency], [Rpt_PL_Msr].[Value] ))))}
I will let you digest that one for a minute, although we have discussed all functions used.
Generate( TM1SubsetAll([Dim_1]), Filter( TM1SubsetAll([Dim_2]), [Dim_2].CurrentMember.Name = [Dim_1].CurrentMember.Name))
In this example, the subset will be created in the dimension Dim_2. Adapted from here.
Except( TM1FilterByLevel( TM1SubsetAll([Balance Sheet Account]), 0), Generate( TM1FilterByLevel( TM1SubsetAll([_S-General Ledger Account]), 0), Filter( TM1FilterByLevel( TM1SubsetAll([Balance Sheet Account]), 0), [Balance Sheet Account].CurrentMember.Name = [_S-General Ledger Account].CurrentMember.Name)))
Yes, that's correct, it's lengthy. And an ElementIndex (Dimix) function in a TI process could do the same. But still useful as MDX serves different purposes. Submitted by George Tonkin, thanks for that.
{ Except( { TM1FilterByLevel( Descendants( {[Customer].[Total Customer by country]} ), 0 )}, { TM1FilterByLevel( Descendants( {[Customer].[Total Customer by manager]} ), 0 )} )}
What remains is the elements of the first hierarchy that are not part of the second. Note: to compare elements in different hierarchies in Planning Analytics-speak ('Hierarchies' or Alternative Hierarchies), you need code that is more involved. Tweaking the above with different hierarchy names will not work.
To put you on the right track with dimensions (introduce hierarchies yourself):
Except( TM1FilterByLevel( TM1SubsetAll([ Dimension 1 ]), 0), Generate( TM1FilterByLevel( TM1SubsetAll([Dimension 2]), 0), Filter( TM1FilterByLevel( TM1SubsetAll( [Dimension 1]), 0), [Dimension 1].CurrentMember.Name = [Dimension 2].CurrentMember.Name)))
Unfortunately, alias values will not be picked up. A Dimix or ElementIndex nowadays, is more powerful.
Generate( [dim_B].[700000].Children, Filter( TM1FilterByLevel( TM1SubsetAll([dim_A]), 0), [dim_A].CurrentMember.Name = [dim_B].CurrentMember.Name))
Except( TM1FilterByLevel( Descendants( [Trading Partner].[All by Geography] ), 0 ), {Intersect( TM1FilterByLevel( Descendants( [Trading Partner].[All by Geography] ), 0 ), TM1FilterByLevel( Descendants( [Trading Partner].[IC] ), 0 ))})
Generate( Filter( TM1SubsetAll( [B] ), Len([B].[Alt_Name]) > 0), {StrToMember( "[A].[" + [B].[Alt_Name] + "]")})
Caveat: if the Alt_Name alias is filled in in dimension B, that name has to exist as an element in dimension A ! If it does not, TM1 will throw up an error in the best case, some TM1 versions will even experience a crash ! Thank you Ty Cardin

Head( Filter( TM1SubsetAll( [}Clients] ), [}ClientGroups].([}Groups].[ADMIN]) = "ADMIN" ), 1 )
Hierarchize( Generate( TM1SubsetToSet([}Clients], "users" ), Filter( TM1SubsetAll([}Groups]), [}ClientGroups].([}Clients].CurrentMember) <> "" )))
"users" is a (public) subset containing the users you would like to evaluate. Most probably this subset will only contain 1 element but you are free to have multiple users. The result of the MDX expression, group names, can be copy/pasted elsewhere - for example in other security cubes.
You can also have other logic instead of SubsetToSet, adjust that part of the expression to suit.
With a Turbo Integrator process to automate the task:
m = 'Test users'; n = Expand( 'Groups linked to subset %m%' ); If( SubsetExists( '}Clients', m ) = 0 ); SubsetCreate( '}Clients', m ); EndIf; If( SubsetExists( '}Groups', n ) = 0 ); SubsetCreateByMDX( n, Expand( 'Hierarchize( Generate( TM1SubsetToSet([}Clients], "%m%" ), Filter( TM1SubsetAll([}Groups]), [}ClientGroups].([}Clients].CurrentMember) <> "" )))'), '}Groups' ); EndIf;
Below you will find similar code.
Generate( TM1SubsetToSet([}Groups], "Groups subset" ), Filter( TM1SubsetAll([}Clients]), [}ClientGroups].([}Groups].CurrentMember) <> "" ))
"Groups subset" is a (public) subset containing the groups you would like to evaluate. Most probably this subset will only contain 1 element but you are free to have multiple groups. The result of the MDX expression, client names, can be used elsewhere.
Subsets based on other objects
SubsetCreateByMDX( 'Target subset', 'TM1SubsetToSet( [Account], "Source subset" )' );
The source subset will probably be dynamic but that's not a requirement. After the previous line to create the subset, you can still add or remove elements in the target subset such that, as an added benefit, the target subset becomes static.
[Continue reading on this in the next paragraph.]
Or retrieve all elements of that dimension:
SubsetCreateByMDX( 'Target subset', 'TM1SubsetAll( [Account] )' );
Or all elements in a dimension Account2 that also exist in the dimension Account:
SubsetCreateByMDX( 'Target subset', 'Generate( TM1SubsetAll([Account]), Filter( TM1SubsetAll([Account2]), [Account].CurrentMember.Name = [Account2].CurrentMember.Name))' );
Finally, all elements in a dimension Account2 that also exist in the subset 'Filter by level 0' in the dimension Account:
SubsetCreateByMDX( 'Target subset', 'Generate( TM1SubsetToSet([Account], "Filter by level 0"), Filter( TM1SubsetAll([Account2]), [Account].CurrentMember.Name = [Account2].CurrentMember.Name))' );
The latter expression is a winner, it saves you from writing a loop over subset elements.
StrToSet( Iif( Count( Filter( TM1SubsetAll([Company]), [Company].CurrentMember.Properties("Active") = "Y" )) > 0, "Filter( TM1SubsetAll( [Company]), [Company].CurrentMember.Properties(""Active"") = ""Y"" )", "TM1SubsetAll([Company])" ))
If there are Active companies, filter those out. If there are No Active companies, return all companies.
The function StrToSet is not my favorite to be honest. Working with text to generate an MDX query is second best in my opinion.
Does anyone know a better way to achieve the same result ?
Distinct elements
{ Distinct( TM1SubsetAll( [PL_Account] ))}
or based on an existing subset:
{ Distinct( TM1SubsetToSet( [PL_Account], "YOUR_SUBSET_NAME" ))}
Keep in mind though that Distinct({MDX Statement}) is not the same as starting with TM1SubsetAll. Distinct is looking for unique MUNs (Member Unique Name), dimension paths towards an element or elements.
[Product].[Product].[New Products^A] is a different member than [Product].[Product].[Products On Sale^A]
Refer to this topic on removing duplicate elements.
TM1FilterByLevel( TM1SubsetAll( [Customer] ), 2 )
TM1FilterByLevel( Descendants( {[Customer].[Selections]} ), 2 )
Set 2 contained more elements than set 1. The right comparison is to filter in case 1 on all MUNs:
TM1FilterByLevel( Distinct( [Customer].Members ), 2)
This dimension happened to have a lot of cases where the same-named element appears in many parts of the dimension.
dDimName = 'Versions';
# the operator +
SubsetCreateByMDX( '1', Expand( '{{[%dDimName%].[Planning]} + {[%dDimName%].[Budget]} +
{[%dDimName%].[%PriorMonthForecast%]} + {[%dDimName%].[Jan Forecast]} + {[%dDimName%].[Mar Forecast]} +
{[%dDimName%].[%PriorMonthSnapshot_1%]} + {[%dDimName%].[%PriorMonthSnapshot_2%]}}' ));
# the function Union, which only works on pairs
SubsetCreateByMDX( '2', Expand( 'Union( {[%dDimName%].[Planning]}, { {[%dDimName%].[Budget]},
{[%dDimName%].[%PriorMonthForecast%]}, {[%dDimName%].[Jan Forecast]}, {[%dDimName%].[Mar Forecast]},
{[%dDimName%].[%PriorMonthSnapshot_1%]}, {[%dDimName%].[%PriorMonthSnapshot_2%]} } )' ));
# function Distinct
SubsetCreateByMDX( '3', Expand( 'Distinct( { {[%dDimName%].[Planning]}, {[%dDimName%].[Budget]},
{[%dDimName%].[%PriorMonthForecast%]}, {[%dDimName%].[Jan Forecast]}, {[%dDimName%].[Mar Forecast]},
{[%dDimName%].[%PriorMonthSnapshot_1%]}, {[%dDimName%].[%PriorMonthSnapshot_2%]} } )' ));
# Distinct with condensed coding (double Expand function is needed)
d = '[%dDimName%].';
SubsetCreateByMDX( '4', Expand( Expand( 'Distinct( { %d%[Planning], %d%[Budget], %d%[%PriorMonthForecast%],
%d%[Jan Forecast], %d%[Mar Forecast], %d%[%PriorMonthSnapshot_1%], %d%[%PriorMonthSnapshot_2%] } )' )));
Orphans and top consolidations
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 0), [Accounts].CurrentMember.Parent.Name = "" )}
Or:
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 0), Count([Accounts].CurrentMember.Ancestors) = 0)}
Or:
{Filter( Filter( TM1SubsetAll([Accounts]), [Accounts].CurrentMember.Parent.Name = ""), Isleaf( [Accounts].CurrentMember ))}
{Filter( TM1SubsetAll([Accounts]), [Accounts].CurrentMember.Parent.Name = "" )}
{Filter( TM1SubsetAll([Accounts]), [Accounts].CurrentMember.Parent.Name = "" )}
[dimension].[hierarchy].CurrentMember.Properties("ELEMENT_TYPE") = "1" or "2" of "3"
In Turbo Integrator, have a look at the DimensionTopElementName function too. {Except( Filter( TM1SubsetAll( [Accounts] ), [Accounts].CurrentMember.Parent.Name = "" ), {TM1FilterByLevel( TM1SubsetAll( [Accounts] ), 0 )} )}
Wrapping this statement in the TM1SortByIndex function can be useful.
Alternative shorter expression:
[Accounts].Levels(0).Members
Here I used the levels of a dimension/hierarchy, as discussed above.
This works too:
[Accounts].[level000].Members or even [Accounts].[Top accounts].Members if you gave that specific level000 a clear name (which is good practice in TM1 by the way !). Please refer to the IBM site
Should a subset exist with the same name as a named level, then here the named level takes precedence.
Filter( Filter( TM1SubsetAll([Accounts]), [Accounts].CurrentMember.Parent.Name = ''), TM1TupleSize(Intersect({[Accounts].[600000]}, Descendants({[Accounts].CurrentMember})).Item(0)) > 0 )
This expression features the function TM1TupleSize to return the number of members in a tuple.
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 1), Isleaf( [Accounts].CurrentMember ))}
Alternatively:
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 1), [Accounts].CurrentMember.FirstChild.Name = "")}
Alternatively:
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 1), Count([Accounts].CurrentMember.Children) = 0)}
Alternatively:
{Filter( TM1FilterByLevel( TM1SubsetAll([Accounts]), 1), TM1TupleSize( ([Accounts].CurrentMember.Children).Item(0)) = 0)}
With the TM1 REST API:
/api/v1/Dimensions('Accounts')/Hierarchies('Accounts')/Members?$select=Name&$expand=Element($select=Type),Children/$count&$filter=Element/Type eq 3 and Children/$count eq 0
Source
Filter( TM1SubsetAll( [Revenue_Msr] ), [Revenue_Msr].CurrentMember.Properties("ELEMENT_TYPE") = "1" )
"1" = type N (Numeric, level 0), "2" = type S (String, text), "3" = type C (Consolidated, level > 0 )
Thanks to George Tonkin.
{Filter( Filter( TM1SubsetAll([Revenue_Msr]), Count([Revenue_Msr].CurrentMember.Ancestors) > 0), [Revenue_Msr].CurrentMember.Properties("MEMBER_WEIGHT") <> "1.000000")}
Better would be to convert textual values to a number with StrToValue:
{Filter( Filter( TM1SubsetAll([Revenue_Msr]), Count([Revenue_Msr].CurrentMember.Ancestors) > 0), StrToValue([Revenue_Msr].CurrentMember.Properties("MEMBER_WEIGHT")) <> 1)}
If( HierarchyHasOrphanedLeaves( 'Dimension name', 'Hierarchy name' ) = 1 ); # The hierarchy contains orphaned leaves, take action if needed EndIf;
TM1 users and groups
{StrToMember( "[}Clients].[" + USERNAME + "]")}
Alternatively:
{TM1FilterByPattern( TM1SubsetAll( [}Clients] ), USERNAME )}
{[}Clients].[whoami].Item(0)}
Or:
TM1SubsetToSet([}Clients], "whoami")
Or:
{TM1Member([}Clients].[whoami].Item(0),[}Clients])}
Filter( [}Groups].Members, [}ClientGroups].( [}Clients].[' | vUser | '] ) <> "" )
Note that the resulting subset could be empty.
Filter( [}Groups].Members, [}ClientGroups].( StrToMember( "[}Clients].[" + USERNAME + "]")) <> "" )
Note that the resulting subset could be empty.
# Make sure the }ClientPropertiesSyncInterval=5 is present in the TM1s.cfg file c0 = 'Active clients security'; vCube = '}ClientGroups'; vDim_1 = '}Clients'; vDim_2 = '}Groups'; ## start from scratch If( ViewExists( vCube, c0 ) > 0 ); ViewDestroy( vCube, c0 ); SubsetDestroy( vDim_1, c0 ); SubsetDestroy( vDim_2, c0 ); EndIf; # create subsets in the relevant dimensions SubsetCreateByMDX( c0, Expand( 'TM1Sort( Filter( TM1SubsetAll( [%vDim_1%] ), [}ClientProperties].([}ClientProperties].[STATUS]) = "ACTIVE" ), Asc )' ), vDim_1 ); SubsetCreateByMDX( c0, Expand( 'TM1Sort( Hierarchize( Generate( Filter( TM1SubsetAll( [%vDim_1%] ), [}ClientProperties].([}ClientProperties].[STATUS]) = "ACTIVE" ), Filter( TM1SubsetAll( [%vDim_2%] ), [%vCube%].([%vDim_1%].CurrentMember) <> "" ))), Asc )' ), vDim_2 ); # apply an Alias If( Dtype( '}ElementAttributes_}Clients', '}TM1_DefaultDisplayValue' ) @= 'AA' ); SubsetAliasSet( vDim_1, c0, '}TM1_DefaultDisplayValue' ); EndIf; If( Dtype( '}ElementAttributes_}Groups', '}TM1_DefaultDisplayValue' ) @= 'AA' ); SubsetAliasSet( vDim_2, c0, '}TM1_DefaultDisplayValue' ); EndIf; # create a view ViewCreate( vCube, c0 ); # add subsets to the view ViewSubsetAssign( vCube, c0, vDim_1, c0 ); ViewSubsetAssign( vCube, c0, vDim_2, c0 ); # the view layout ViewRowDimensionSet( vCube, c0, vDim_1, 1 ); ViewRowDimensionSet( vCube, c0, vDim_2, 2 ); ViewSuppressZeroesSet( vCube, c0, 1 );
TM1Sort( Filter( TM1SubsetAll( [}Clients] ), [}ClientProperties].([}ClientProperties].[STATUS]) = 'ACTIVE' ), Asc )
Precondition is that in the TM1s.cfg file, we add a property: ClientPropertiesSyncInterval=5 (a dynamic property, no need to restart TM1)
TM1 stores the output in the }ClientProperties cube in a measure called "STATUS"
5 is the number of seconds at which the list of active users is refreshed.
To disable it, use 0 or leave out the property.
Filter( [}Groups].Members, [}ClientGroups].( StrToMember( "[}Clients].[" + USERNAME + "]")) <> "" )
Note that the resulting subset could be empty.
Application and control objects
TM1Sort( Except( TM1SubsetAll( [}Cubes] ), TM1FilterByPattern( TM1SubsetAll( [}Cubes] ), "}*" )), Asc)
Likewise for processes, dimensions, … TM1Sort( Except( TM1SubsetAll( [}Dimensions] ), TM1FilterByPattern( TM1SubsetAll( [}Dimensions] ), "}*" ) ), Asc)
TM1Sort( {TM1FilterByPattern( TM1SubsetAll( [}Cubes] ), "}*" ), Asc)
Likewise for processes, dimensions, …
When you look at the Microsoft links I mentioned above, you will find a lot more functions. Including functions for information on the dimension structure: FirstSibling, Parent, Children, FirstChild / LastChild, Ancestors, and so on. Many other options for creating dynamic subsets are explained on that webpage. It is a must read!
Temporary subsets
Needless to say, but these subset definitions using MDX syntax can be used in the function SubsetCreatebyMDX. That function can also create temporary subsets as of TM1 10.2.2 FP4 (see here).
TM1ELLIST
The function TM1ELLIST in a Planning Analytics For Excel spreadsheet can return an array of elements from a hierarchy. Interesting twist is that the list can be driven by an MDX. This opens many doors that were previously hard to open. The workaround of having a dynamic report (active form) was not elegant. Nor the workaround of having to array-enter the SUBNM formula in "enough" cells, knowing that it would need the MDX dynamic subset be part of the hierarchy. A fully dynamic MDX in a spreadsheet to drive a selection… nada ! Now we can.
You can just enter in a cell like A1:
=TM1ELLIST("CXMD:}Clients",,,,,"Head( TM1SubsetAll( [}Clients] ), 10 )")
and the result will spill down in the cell and 9 cells below - unless you have less than 10 users in the model.
No need for array-entering the formula with Ctrl-Shift-Enter to receive the curly braces left and right
of the formula. You now enter the world of dynamic arrays in Excel.
For those using VBA to generate the formula, consider:
Sub create_ellist()
Dim vMDX As String
vMDX = "TM1FilterByLevel( TM1SubsetAll( [Year] ), 0 )"
'creating a TM1ELLIST function as a dynamic array
Range("A1").Formula2 = "=TM1ELLIST(""servername:Year"",,,,,""" & vMDX & """)"
Range("B1").Formula2 = "=""Y"" & A1#"
End Sub
The result are Year elements in column A, and the same elements prefixed with a "Y" in the corresponding cells in column B.
Lists in Planning Analytics For Excel provide similar functionality. They could provide a good alternative for dynamic reports in case you just want to return hierarchy members with some attributes or security information.
IS
The IS keyword can be used as well. If you remember the dynamic subsets we created to filter elements by levels, named appropriately in the
}HierarchyProperties control cube, this can be written with IS as well:
Filter( TM1SubsetAll( [Period_MDX] ), [Period_MDX].CurrentMember.Level IS Semester )
In case the name of the level is a reserved keyword or there happens to be a dimension with the same name, you should fully qualify the name:
Filter( TM1SubsetAll( [Period_MDX] ), [Period_MDX].CurrentMember.Level IS [Period_MDX].[Year] )
Another secret found by George Tonkin.
Count
We have used the function Count before, but it's a good idea to list some of the many use cases (input by Philip Bichard):
- how many bad debtors do we have ?
- how many cost centres are late with their budget submission
- how many customers did not buy from us in the last 12 months
- etc.
Escape character
Filter( TM1SubsetAll([Line]), [inputcube].([measure].[Text]) = "my ""quoted text""" )
When you are filtering out elements that should match a pattern with a double quote, use the same trick (here we look for the element "quoted text" surrounded by quotes):
TM1FilterByPattern( TM1SubsetAll([Line]), """qu*ed text""")
Lastly, it is identical for the Instr function (here we look for elements containing "quoted):
Filter( TM1SubsetAll( [Line] ), Instr( [Line].CurrentMember.Name, """quoted" ) > 0 )
Caveats
A few caveats apply. If you create a dynamic subset in TI (the function is called SubsetCreatebyMDX('NAME OF THE SUBSET', 'MDX EXPRESSION'), make sure you always have at least 1 element that matches. If not, the process errors out. Unless you use TM1 10.1 or later, where an undocumented 3rd parameter to the function equal to the dimension name, will avoid the error in case no elements satisfy the expression. As an alternative, in that case you should loop over the dimension elements and insert the matching elements in a static subset SubsetCreate('DIMENSION NAME', 'SUBSET NAME') and SubsetElementInsert('DIMENSION NAME', 'SUBSET NAME', 'ELEMENT NAME', POSITION). The latter technique will always work (unless you are stuck in an endless loop like me on some Monday mornings), whichever you will use depends on your liking and coding skills.
Please do NOT use the function TM1SubsetBasis() (unless you know what you are doing). Even though the MDX expression recorder generates such code, it is in fact not to be used. It refers to a relative selection of elements ('at the time of using the function') rather than an absolute selection of elements ('it will always be the same selection/result, all else being equal').
Excel
In Excel spreadsheets, we can work with MDX queries to return a subset: for example in active forms. There, you could store the MDX query in a (hidden) cell. The query expression could be chopped up to include cell references. For instance, the user can choose a Product family in cell H10, and the active form returns the data on the lowest-level children of that Product family. Mind that there could be a 256 characters limit for the MDX expression for older versions of TM1. You COULD leave out the dimension names BUT then the element names must be unique throughout the ENTIRE TM1 model (over all dimensions).
MDX Views
Now that you are a full-blown expert on MDX in Planning Analytics, the party's only started. You can have cube views based on MDX expressions too. Since this is a broad topic on its own, here is an example of what an MDX view might look like:
SELECT NON EMPTY {TM1FilterByLevel( TM1SubsetAll( [Company].[Company] ), 0)} ON 0, NON EMPTY { {[Account].[Account].[EBITDA]}*{DrillDownLevel( {[CostCenter].[CostCenter].[Total Cost Center]} )}, {TM1FilterByLevel( TM1SubsetAll( [Account] ), 0)}*{TM1FilterByLevel( TM1SubsetAll( [CostCenter].[CostCenter] ), 0)}} ON 1 FROM [Rpt_ProfitLoss] WHERE ([Scenario].[Scenario].[Actual], [Year].[Year].[2025], [Period].[Period].[9 YTD], [Currency].[Currency].[EUR])
Likewise for processes, dimensions, …
ON 0 can be substituted for ON COLUMNS. ON 1 can be substituted for ON ROW. You may swap rows and columns in the MDX view definition if you find it easier to understand.
Views like this were not possible in Architect/Perspectives. Views like this can be the data source to a TI process. They are stored with extension xbv in the data directory. xbv stands for "Expression-Based View".
You can go definitely crazy here since you would apply any MDX syntax you already learnt on this page ! :-)
Thank you
One of the many nice emails I received over the years !