Double counting elements
- May. 29, 2017
| Example files with this article: | |
Introduction
Dimensions are the building blocks in TM1 with which you form cubes. The cubes contain the data. Each single data position references 1 element in each of the dimensions of the cube. Hence, the data is associated to elements that are part of the dimensions.
These elements need to be unique within the dimension. Other than that, TM1 does not impose rules on the dimensions. That is, you can create your own elements (lowest level and consolidated) such that you can reach your goals of budgeting, reporting, forecasting, ...
The above means that you are free to create dimensional structures where 1 element rolls up into multiple parents. In itself that is useful and often desired functionality in TM1. However, when the structures are such that element(s) roll up in multiple elements leading to the same parent element(s), then double counting occurs.
Example
It will be evident that in the below illustration, the element 'Totaal Project' is prone to have a wrong result. It will include the values of 'Project 4' twice. In TM1, we can set weights on the elements within their parent element. So it is possible that below, element weights are not always 1. In any case, it looks suspicious and we definitely want to be informed of potential double countings. Unfortunately, TM1 does not have a way to show this information.

Let's have TI automate the job!
I took this exercise upon me and honestly, it has proven to be difficult. In theory, every element can roll up into every other (consolidated) element, so that many billions of combinations are not an exception once the dimension counts over a couple of 1000 elements and is not rather flat. We definitely need to avoid looping over all those combinations, or we will not succeed.
I posted my solution online at the TM1 forum: Double counting elements in a dimension. Please download the 2 TI processes at the top of this page as the code is more recent than the code at the forum. You execute part 1, which then executes part 2.
This process can provide output / change existing TM1 objects in the following ways:
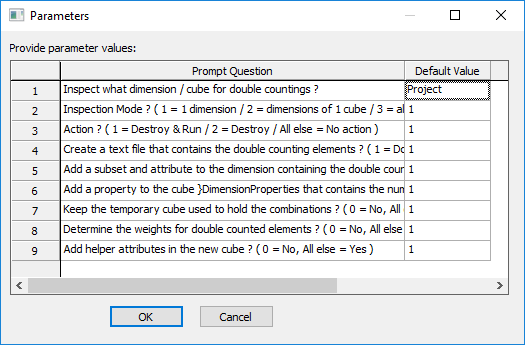
- by creating a text file in the TM1 logging directory, containing the double countings per dimension ( pOutput_CreateTextFile )
- by adding a subset to the dimension being investigated, containing the double countings ( pOutput_AddSubsetToOriginalDim )
- by adding a dimension property to the cube }DimensionProperties, containing the number of double countings per dimension ( pOutput_AddDimensionProperty )
- by creating and not deleting a new cube called '}TECH_Double_Countings' ( pOutput_KeepTempCube )
Element weightings (cfr. infra) can be shown in a cube. They show the effect of 1 element on another, indicating the effect of the double counting.
The parameter pMode determines to what extent dimensions will be inspected:
- If pMode = 1, you inspect 1 dimension. Specify the dimension name in pName.
- If pMode = 2, you inspect all dimensions of a cube. Specify the cube name in pName.
- If pMode = 3, you inspect all application dimensions and create a 'light' output. pName is ignored.
- If pMode = 4, you inspect all application dimensions and create a 'full' output. pName is ignored.
- If pMode = 5, you can insert a measure in the cube }DimensionProperties where you can skip dimensions from the treatment. pName is ignored.
You need TM1 10.2.2 FP6 or higher to execute the processes.
Results / suggested way of using the code in a real TM1 model
For the above mentioned very simple Project dimension:



All screenshots above show output of the generic processes. There is a cube that you can consult, showing the double counted elements, the total weight, and the number of parents that the child element has. There is a subset on the original Project dimension, and on that dimension there is also an attribute containing elements and weights. And there is a text file. So there is abolutely no single reason why you can skip/forget double countings from now on ;-)
After having applied the code to a number of TM1 models, these are my results:
- usually the Period / Month dimension has double countings. For example, a 'YTD' consolidation groups 12 consolidated YTD elements for the periods (no double counting) but underneath the 12 YTD elements you have the level 0 periods. These roll up several times in the "YTD" element. This is okay and not a problem.
- I have seen dimensions for Cost centers, Accounts, Products, Employees and many more suffering from double countings. This can be problematic and the exact reason why I wrote these processes.
- my best advice to use the tool is:
- Run the tool once with "pMode = 5". The other parameters do not matter here. You create a }DimensionProperties element
- Single out the large dimensions with a high DNLEV and run the tool with "pMode = 1" for these dimensions. Inspect the results in attributes, subsets and a text file.
- When you are done with these big dimensions, put a 1 for these dimensions in the }DimensionProperties cube on the measure "Skip dimension for double counting"
- Run the tool with "pMode = 3" or "pMode = 4". 4 gives a richer output than 3 but it could take somewhat longer.
Good luck !
